Starting (on finite domains) with Gaussian processes
Gaussian processes are wonderful. Let’s take a look at the machinery behind them in the simplest case: when they are just a multivariate normal distribution.
Author
Paweł Czyż
Published
February 12, 2024
Let \(Y = (Y_1, \dotsc, Y_n)^T\) be a random variable distributed according to the multivariate normal distribution \(\mathcal N(\mu, \Sigma)\), where \(\mu\in \mathbb R^n\) and \(\Sigma\) is a real symmetric positive-definite1\(n\times n\) matrix.
We will think of this distribution in the following manner: we have a domain \(\mathcal X = \{1, 2, \dotsc, n\}\) and for each \(x\in \mathcal X\) we have a random variable \(Y_i\) and the joint distribution \(P(Y_1, \dotsc, Y_n)\) is multivariate normal.
Assume that we have measured \(Y_x\) variables for indices \(x_1, \dotsc, x_k\), with corresponding values \(Y_{x_1}=y_1, \dotsc, Y_{x_k}=y_k\), and we are interested in predicting the values at locations \(x'_1, \dotsc, x'_q\), i.e., modelling the conditional probability distribution \[
P(Y_{x'_1}, \dotsc, Y_{x'_q} \mid Y_{x_1}=y_1, \dotsc, Y_{x_k}=y_k).
\]
We will also allow \(k=0\), i.e., we would like to access marginal distributions. This can be treated as an extension of the problems answered by bend and mix models we studied here.
Formalising the problem
To formalise the problem a bit:
NoteConditional calculation
Consider a set of measured values \(M = \{(x_1, y_1), \dotsc, (x_k, y_k)\}\) and a non-empty query set \(Q = \{x'_1, \dotsc, x'_q\} \subseteq \mathcal X\).
We assume that \(Q\cap M_x = \varnothing\) and \(|M_x| = |M|\), where \(M_x = \{x \in \mathcal X \mid (x, y)\in M \text{ for some } y \}\).
We would like to be able to sample from the conditional probability distribution \[
P(Y_{x_1'}, \dotsc, Y_{x_q'} \mid Y_{x_1}=y_1, \dotsc, Y_{x_k}=y_k)
\] as well as to evaluate the (log-)density at any point.
We allow \(M=\varnothing\), which corresponds then to marginal distributions.
This problem can be solved for multivariate normal distributions by noticing that all conditional (and marginal) distributions will also be multivariate normal. Let’s introduce some notation.
For a tuple \(\pi = (\pi_1, \dotsc, \pi_m) \in \mathcal X^m\) such that \(\pi_i\neq \pi_j\) for \(i\neq j\), we will write \(Y_\pi\) for a random vector \((Y_{\pi_1}, \dotsc, Y_{\pi_m})\). Note that this operation can be implemented using a linear mapping \(A_\pi \colon \mathbb R^n\to \mathbb R^m\) with \[
A_\pi \begin{pmatrix} Y_1 \\ \vdots \\ Y_n \end{pmatrix} = \begin{pmatrix}
Y_{\pi_1} \\ \vdots \\ Y_{\pi_m}
\end{pmatrix}
\] and \((A_\pi)_{oi} = \mathbf 1[ i = \pi_o]\). Hence, \(Y_\pi\) vector is distributed according to \(\mathcal N(A_\pi\mu, A_\pi\Sigma A_\pi^T)\).
The above operation suffices for calculating arbitrary marginal distributions and distributions corresponding to permuting the components.
Consider now the case where we want to calculate a “true” conditional distribution (i.e., with \(M\neq \varnothing\)), so the marginalisation does no suffice.
We can use the tuple \(\pi = (x_1', \dotsc, x_q', x_1, \dotsc, x_k)\) to select the right variables and reorder them into a \(q\)-dimensional block of unobserved (“query”) variables and a \(k\)-dimensional block of observed (“key”) variables2.
Note 1: Conditioning multivariate normal
Let \(Y=(Y_1, Y_2) \in \mathbb R^{k}\times \mathbb R^{n-k}\) be a random vector split into blocks of dimensions \(k\) and \(n-k\). If \(Y\sim \mathcal N(\mu, \Sigma)\), where \[
\mu = (\mu_1, \mu_2)
\] and \[
\Sigma = \begin{pmatrix}
\Sigma_{11} & \Sigma_{12} \\
\Sigma_{21} & \Sigma_{22}
\end{pmatrix},
\]
then for every \(y \in \mathbb R^{n-k}\) it holds that
We see that in both formulae the matrix of regression coefficients3\(\color{Apricot}\Sigma_{12}\Sigma_{22}^{-1}\) appears. We will discuss calculation of this term below.
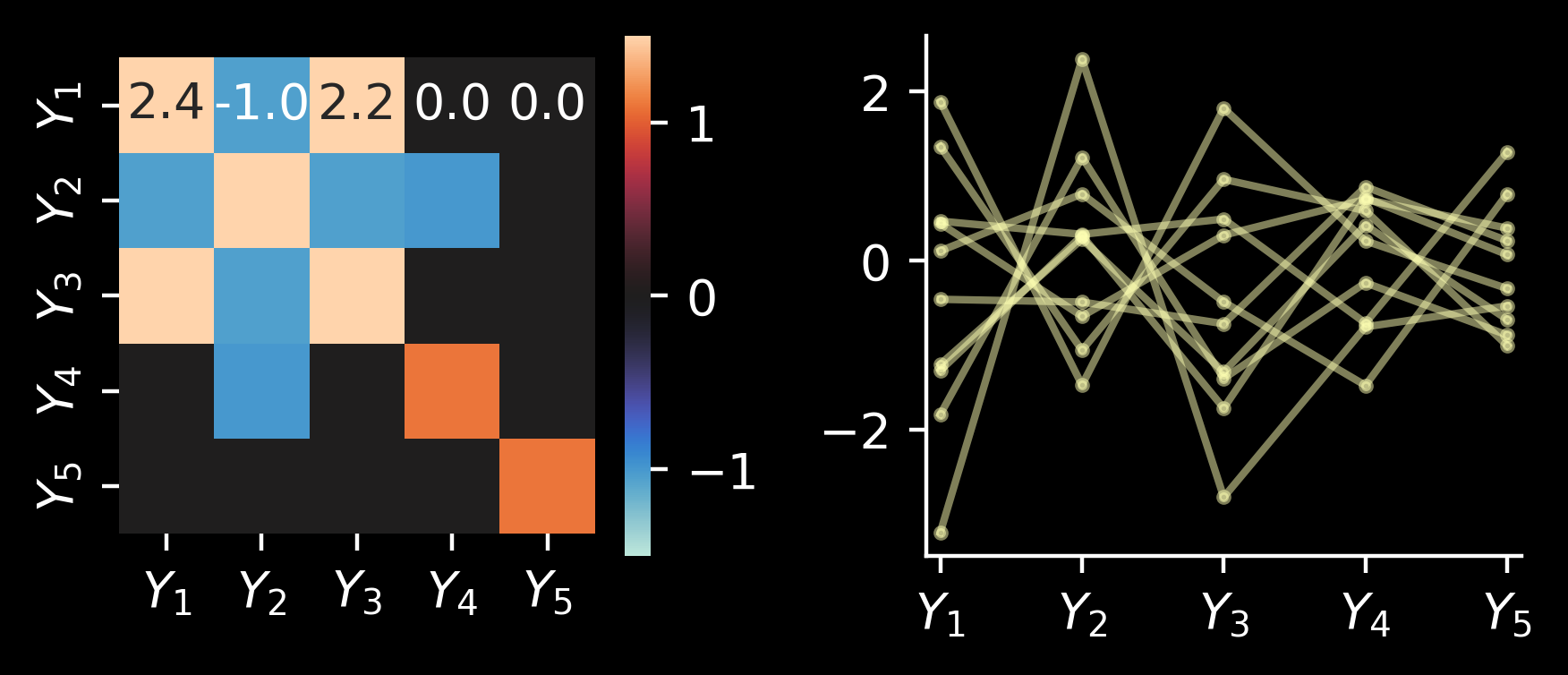
Now we can do conditioning. For example, imagine that we have \(\mu = 0\) and we know \(\Sigma\): \(Y_1\) correlates with \(Y_3\), and \(Y_2\) anticorrelates with \(Y_4\) and \(Y_5\) doesn’t correlate with anything else. We measure \(Y_1\) and \(Y_2\), so we can use this correlation structure to impute \(Y_3\), \(Y_4\) and \(Y_5\).
First, let’s plot the covariance matrix and the samples:
Imagine now that we observed \(Y_1=1.5\) and \(Y_2=1\). We expect that \(Y_3\) should move upwards (the posterior should be shifted so that most of the mass is above \(0\)), \(Y_4\) to go downwards and \(Y_5\) to stay as it was. Let’s plot covariance matrix and draws from the conditional posterior \(P(Y_3, Y_4, Y_5\mid Y_1=1.5, Y_2=1)\):
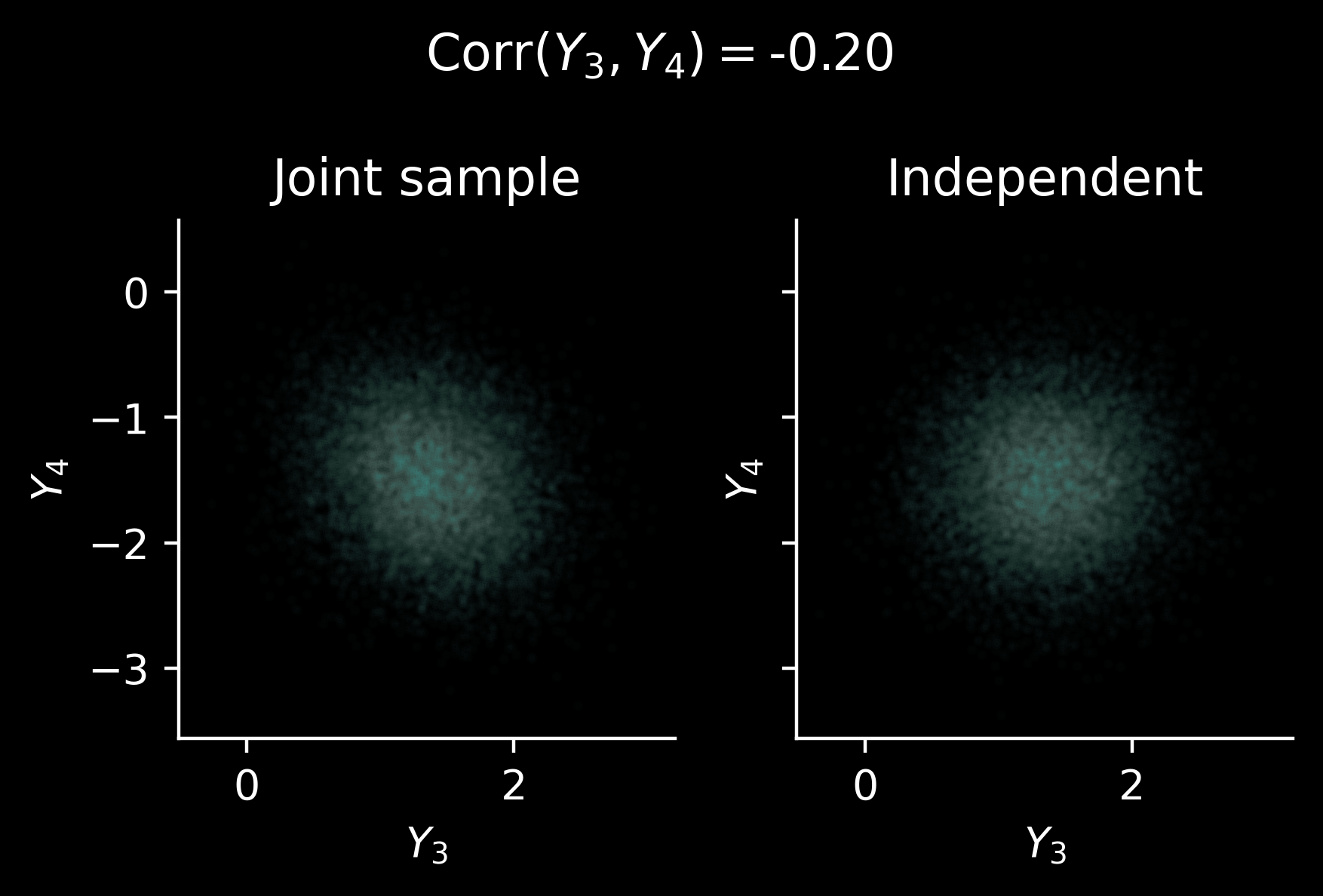
We see that there is slight anticorrelation between \(Y_3\) and \(Y_4\): by sampling from the conditional distribution we obtain a coherent sample. This is different than drawing independent samples from \(P(Y_3 \mid Y_1=y_1, Y_2=y_2)\) and \(P(Y_4\mid Y_1=y_1, Y_2=y_2)\). Perhaps it’ll be easier to visualise it on a scatter plot:
Ok, it’s hard to see, but visible – the (negative) correlation is just quite weak in this case.
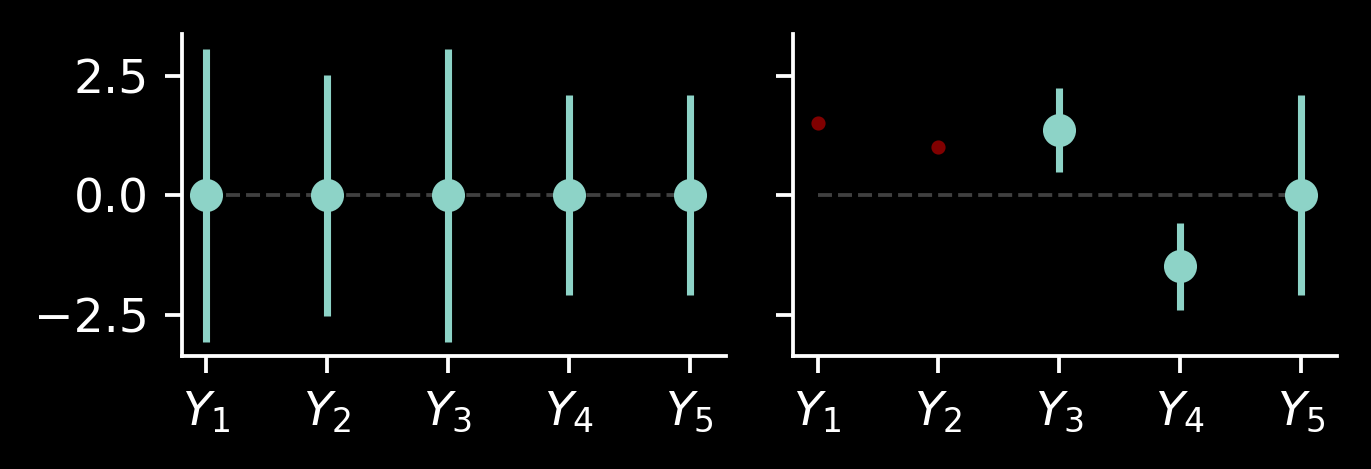
Let’s do the last visualisation before we move to Gaussian processes. As mentioned, the magical thing is the access to the whole posterior distribution \(P(Y_3, Y_4, Y_5 \mid Y_1=y_1, Y_2=y_2)\): we can evaluate arbitrary probabilities and sample consistent vectors from this distribution. We can visualise samples, but sometimes a simpler summary statistic would be useful. Each of the distributions \(P(Y_i \mid Y_1=y_1, Y_2=y_2)\) is one-dimensional Gaussian, so we can plot its mean and standard deviation. Or, even better, let’s plot \(\mu_i\pm 2\sigma_i\) to see where approximately 95% of probability lies.
We’ll plot these regions both before and after conditioning:
As mentioned, these plots don’t really allow us to look at correlations between different variables, but they are still useful: we can easily see that the posterior of \(Y_3\) moved upwards and \(Y_4\) moved downwards! Variable \(Y_5\), which is independent of \((Y_1, Y_2, Y_3, Y_4)\), doesn’t change: if we want to know it, we just have to measure it.
Gaussian processes
For \(\mathcal X = \{1, \dotsc, n\}\) we considered an indexed collection of random variables \(\{Y_x\}_{x\in \mathcal X}\). Let’s call it a stochastic process.
This stochastic process has the property that the joint distribution over all variables was multivariate normal. From that we could deduce that distributions \(P(Y_{x_1}, \dotsc, Y_{x_m})\) were again multivariate normal, what in turn allowed us to do prediction via conditioning (which resulted, again, in multivariate normal distributions).
Let’s move beyond a finite dimension: take \(\mathcal X=\mathbb R\) and consider a stochastic process \(\{Y_x\}_{x\in \mathcal X}\). We will say that it’s a Gaussian process if for every finite set \(\{x_1, \dotsc, x_m\}\subseteq \mathcal X\) the joint distribution \(P(Y_{x_1}, \dotsc, Y_{x_m})\) is multivariate normal. More generally, we can take other domains \(\mathcal X\) (e.g., \(\mathbb R^n\)) and speak of Gaussian random fields.
In either case, the trick is that we never work with infinitely many random variables at once: for example, if we observe values \(y_1, \dotsc, y_k\) at locations \(x_1, \dotsc, x_k\) and we want to predict the values at points \(x'_1, \dotsc, x'_q\), we will construct the joint multivariate normal distribution \(P(Y_{x_1}, \dotsc, Y_{x_m}, Y_{x'_1}, \dotsc, Y_{x'_q})\) and condition on observed values to get the conditional distribution \(P(Y_{x'_1}, \dotsc, Y_{x'_q} \mid Y_{x_1} = y_1, \dotsc, Y_{x_k}=y_k)\).
Now the questions is: how can we define a consistent stochastic process with these great properties? When \(\mathcal X\) was finite, we could just define the joint probability distribution over all variables via mean and covariance. But now \(\mathcal X\) is not finite!
Consider therefore two functions, giving the mean and covariance: \(m \colon \mathcal X\to \mathbb R\) and \(k\colon \mathcal X\to \mathcal X\to \mathbb R^+\). The premise is to build multivariate normal distributions \(P(Y_{x_1}, \dotsc, Y_{x_m})\) by using the mean vector \(\mu_i = m(x_i)\) and covariance matrix \(\Sigma_{ij} = k(x_i, x_j)\).
First of all, we see that not all covariance functions are suitable: we want covariance matrices to be symmetric and positive-definite, so we should use positive-definite kernels.
Secondly, we don’t know if these probability distributions can be coherently glued to a stochastic process. The answer to this problem is provided by Daniell-Kolmogorov extension theorem, which says when a family of probability distributions can be coherently glued yielding a stochastic process. In this case parameterising covariances via \(\Sigma_{ij}=k(x_i, x_j)\) has the properties mentioned in the theorem. On the other hand, parameterising precision matrices via \(k(x_i, x_j)\) doesn’t generally yield a coherent stochastic process.
There are many libraries for working with Gaussian processes, including GPJax, GPyTorch and GPy. We will however just use the code developed above, plus some simple covariance functions.
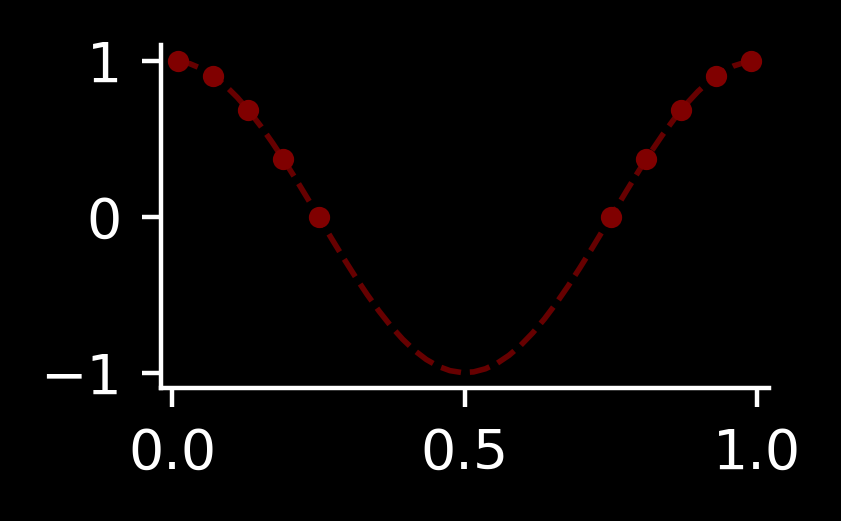
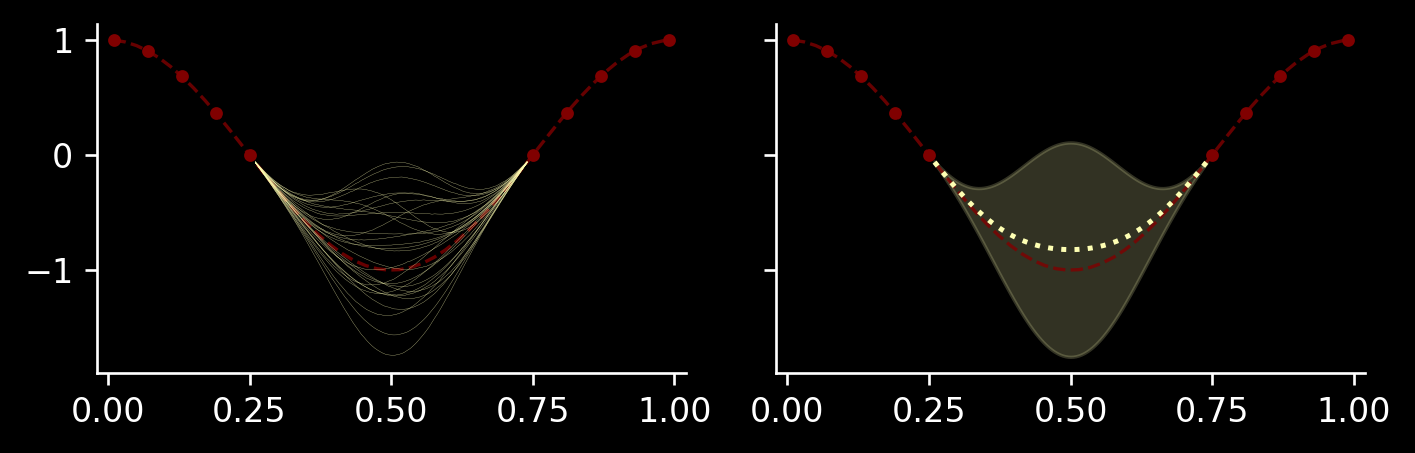
Our task will be the following: we are given some function on the interval \((0, 1)\). We observe some values \(M=\{(x_1, y_1), \dotsc, (x_k, y_k)\}\) inside the intervals \((0, u)\) and \((1-u, 1)\) and we want to predict the function behaviour in the interval \((u, 1-u)\), from which we do not have any data.
We can approach this problem in two ways: first, we can impute missing values evaluated at some points.
For example, we can define a grid over \((u, 1-u)\) with \(q\) query points \(x'_1, \dotsc, x'_q\) and sample from the conditional distribution \(P(Y_{x'_1}, \dotsc, Y_{x'_q} \mid Y_{x_1}=y_1, \dotsc, Y_{x_k}=y_k)\) several times. This is one good way of plotting, showing us the behaviour of the whole sample at once.
Another way of plotting, which we also have already seen, is to take a single point \(x'\) and look at the normal distribution \(P(Y_{x'} \mid Y_{x_1}=y_1, \dotsc, Y_{x_k}=y_k)\), summarized by the mean and standard deviation: we can plot \(\mu(x') \pm 2\sigma(x')\) as a function of \(x'\) (similarly to the finite-dimensional case). This approach doesn’t allow us to look at joint behaviour at different locations, but is quite convenient to summarise uncertainty at a single specific point. For example, this may be informative enough to determine a good location of the next sample to collect in Bayesian optimisation framework (unless one wants to consider multiple points).
Let’s implement an example kernel and plot predictions in both ways:
Nice! I’ve been thinking about showing how different kernels result in differing predictions. But this post is already a bit too long, so I may write another one on this topic. In any case, there’s a Kernel Cookbook created by David Duvenaud.
Appendix
Matrix of regression coefficients
Let’s take a quick look at the matrix of regression coefficients, \(\Sigma_{12}\Sigma_{22}^{-1}\).
Hence, \(X^T\) is a solution to a matrix equation, which we can implement using scipy.linalg.solve. This is considered a better practice as it increases the numerical precision and can be faster (which is visible for large matrices; for small matrices the solution using matrix inversion was often faster).
For every non-zero \(x\in \mathbb R^n\) we have \(x^T\Sigma x > 0\), where the inequality is strict. As \(\Sigma\) is a real symmetric matrix, one of the versions of the spectral theorem yields a decomposition \(\Sigma = R^TDR\) for a diagonal matrix \(D\) and orthogonal \(R\). Hence, equivalently, we all eigenvalues have to be positive. See this link for more discussion.↩︎
I like to call them “query”, “keys” and “values” vectors, which makes the language a bit more similar to transformers. From that we just need one conditioning operation:↩︎
Why is it called in this manner? What are the slopes of \(\mu'\) change, when we vary observed values \(y\)?↩︎