Let’s estimate the mean vector from multivariate normal data.
Author
Paweł Czyż
Published
August 16, 2024
I recently ended up building another Gibbs sampler1. I had \(N\) vectors \((Y_n)\) such that each vector \(Y_n = (Y_{n1}, \dotsc, Y_{nG})\) was assumed to come from the multivariate normal distribution:
\[
Y_n\mid \mu \sim \mathcal N(\mu, \Sigma),
\]
where \(\Sigma\) is a known \(G\times G\) covariance matrix and \(\mu \sim \mathcal N(0, B)\) is the unknown population mean, given a multivariate normal prior. In this case, it is important that we know \(\Sigma\) and that \(B\) is a fixed matrix, which was not necessarily build using \(\Sigma\): the Wikipedia derivation for Bayesian multivariate linear regression (which is a more general case) uses a different prior. I searched the internet for some time and I found a nice project, The Book of Statistical Proofs, but I still could not find the derivation adressing the simple case above.
Let’s quickly derive it. Define \(\nu(x) = \exp(-x/2)\), which has two key properties. First, \(\nu(x)\cdot \nu(y) = \nu(x + y)\). Second, \[\begin{align*}
\mathcal N(x\mid m, V) &\propto \nu\big( (x-m)^T V^{-1}(x-m) \big)\\
&\propto \nu( x^TV^{-1}x - 2m^TV^{-1}x),
\end{align*}
\]
which shows us how to recognise the mean and the covariance matrix of a multivariate normal distribution.
Let’s define \(\bar Y = N^{-1}\sum_{n=1}^N Y_n\) to be the mean vector and \(V = (B^{-1} + N\Sigma^{-1})^{-1}\) to be an auxiliary matrix. (We see that \(V^{-1}\) looks like sum of precision matrices, so may turn out to be some precision matrix!). The posterior on \(\mu\) is given by \[\begin{align*}
p\big(\mu \mid (Y_n), \Sigma, B\big) &\propto \mathcal N( \mu\mid 0, B) \cdot \prod_{n=1}^N \mathcal N(Y_n\mid \mu, \Sigma) \\
&\propto \nu( \mu^T B^{-1}\mu )\cdot \nu\left( \sum_{n=1}^N (Y_n - \mu)^T \Sigma^{-1} (Y_n - \mu) \right) \\
&\propto \nu\left(
\mu^T \left(B^{-1} + N \Sigma^{-1}\right)\mu - 2 N \bar Y^T \Sigma^{-1} \mu
\right) \\
& \propto \nu\left(
\mu^T V^{-1} \mu - 2 N \bar Y^T \Sigma^{-1} (V V^{-1}) \mu
\right) \\
& \propto \nu\left(
\mu^T V^{-1} \mu - 2\left(N \bar Y^T \Sigma^{-1} V\right) V^{-1} \mu
\right).
\end{align*}
\]
Let’s define \(m^T = N\bar Y^T \Sigma^{-1} V\), so that \(m = N \cdot V \Sigma^{-1} \bar Y\). In turn, we have \(p\big(\mu \mid (Y_n), \Sigma, B\big) = \mathcal N(\mu \mid m, V)\).
It looks a bit surprising that we have \(m\) being proportional to \(N\): we would expect that for \(N\gg 1\) we would have \(m\approx \bar Y\). However, this is fine as for \(N\gg 1\) we have \(V \approx N^{-1}\Sigma\) and \(m\approx \bar Y\). For a small sample size, however, the prior regularises the estimate.
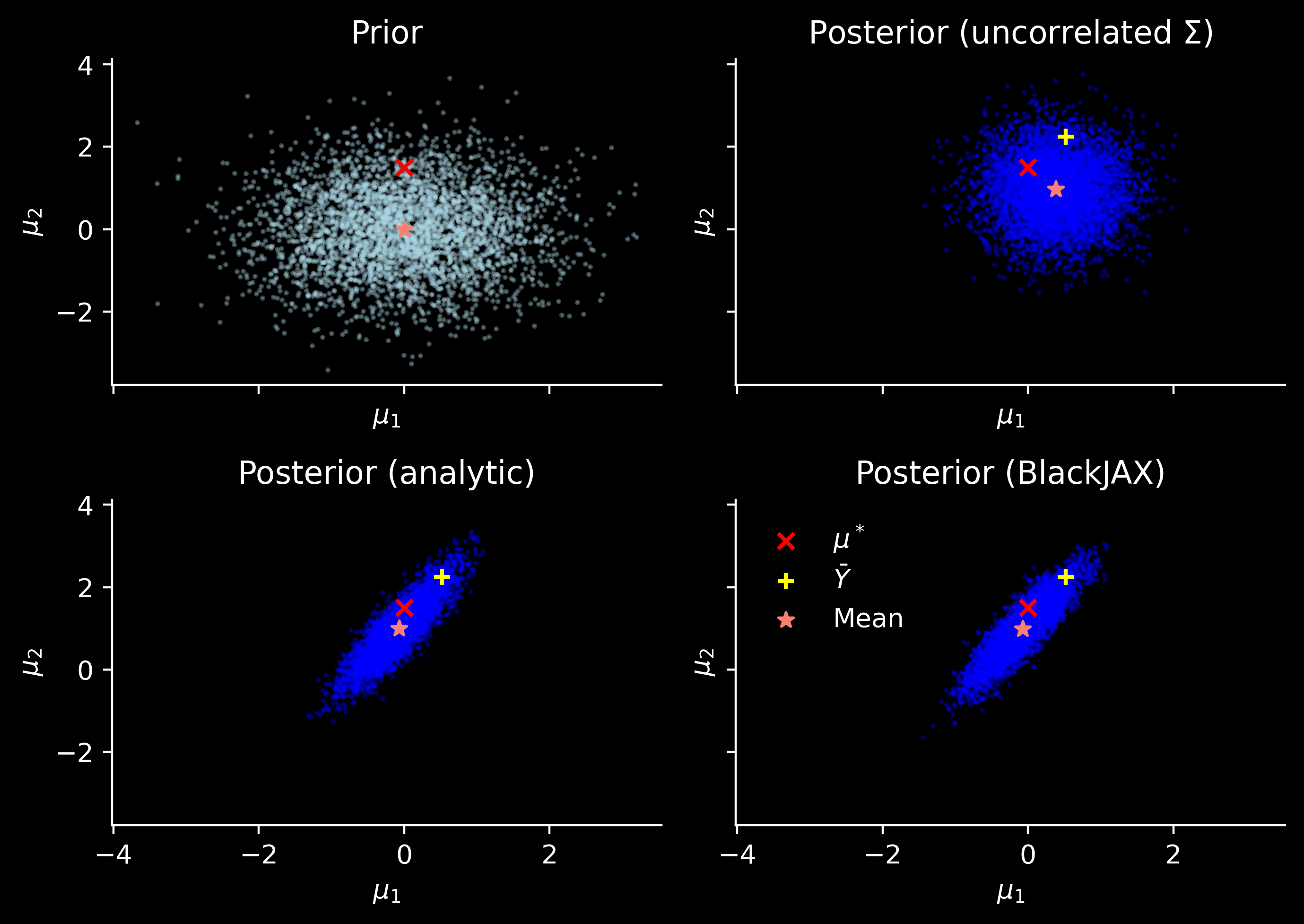
Assume a somewhat wrong \(\Sigma\) matrix, ignoring the offdiagonal terms and retaining only the diagonal ones.
Additionally, we will plot a sample from the prior. On top of that we plot three points: the ground-truth vector \(\mu^*\), data mean \(\bar Y\), and the plotted (prior or an appropriate posterior) distribution mean[^2].
Looks like BlackJAX and analytic formula give the same posterior, so perhaps there is no mistake in the algebra. We also see that using a proper \(\Sigma\) should help us estimate the mean vector better and that using the prior should regularise the inference.
Let’s do several repetitions of this experiment and evaluate the distance from the point estimate to the ground-truth value:
Every method that uses data (i.e., everything apart from the prior) has improved performance when \(N\) increases.
For small sample sizes, using plain data can result in larger errors and a reasonable prior can regularise the posterior mean, so that the error is smaller.
Given enough data, the performance of posterior mean and using the data mean looks quite similar.
Additionally, we see that a model assuming diagonal \(\Sigma\) (i.e., ignoring the correlations) also has performance quite similar to the true one.
This “performance looks similar” can actually be somewhat misleading: each of this distributions has quite large variance, so minor differences can be unobserved.
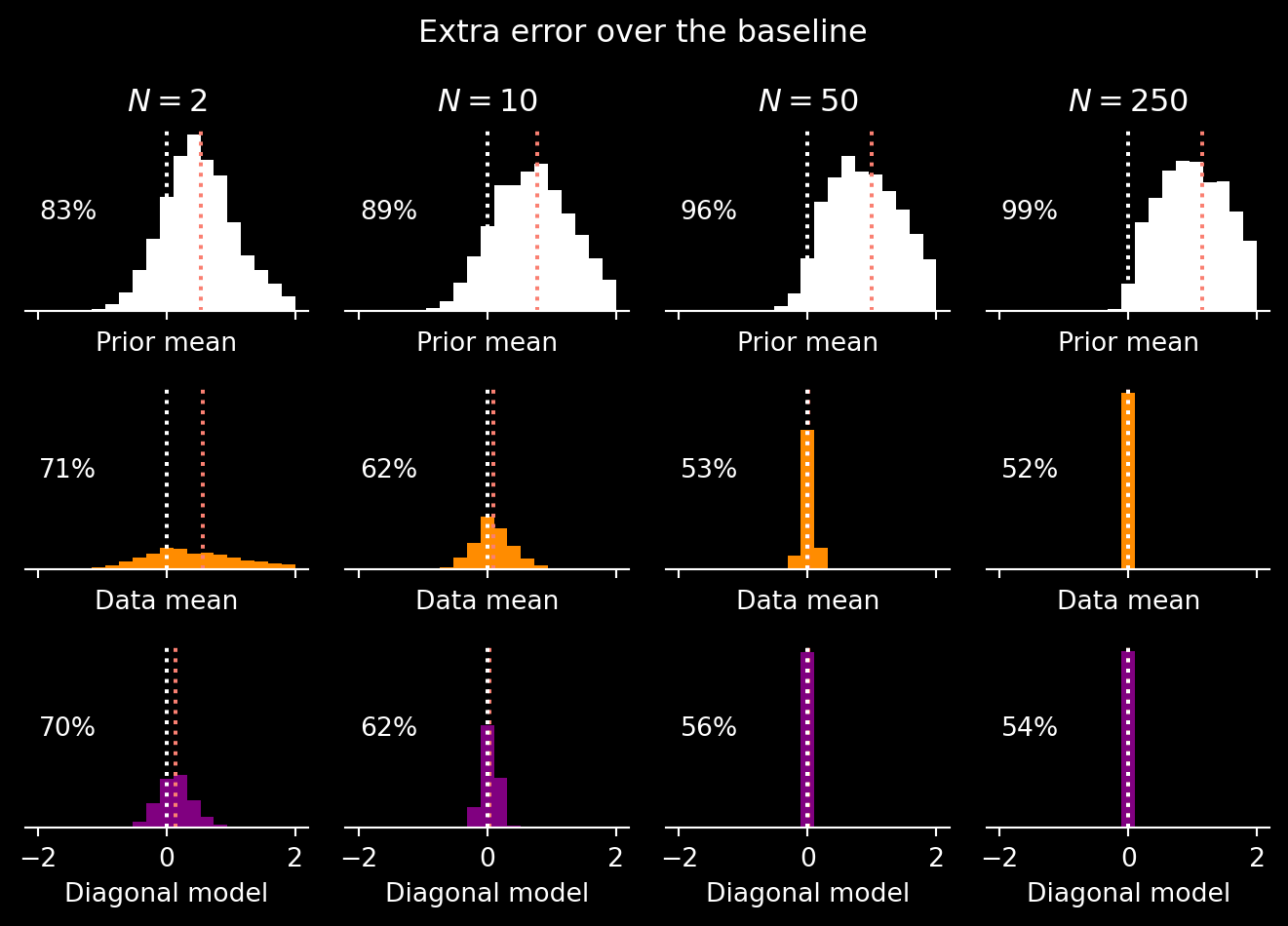
Let’s now repeat this experiment, but this time plotting the difference between distances, so that we can see any difference better. Namely, for the method \(M\) and and the \(s\)-th simulation, write \(d^{(M)}_s\) for the obtained distance. Now, instead of plotting the data sets \(\{ d^{(M_1)}_{1}, \dotsc, d^{(M_1)}_S\}\) and \(\{ d^{(M_2)}_{1}, \dotsc, d^{(M_2)}_S\}\), we can plot the differences \(\{ d^{(M_2)}_{1} - d^{(M_1)}_{1}, \dotsc, d^{(M_2)}_{S} - d^{(M_1)}_{S} \}\).
Let’s use the posterior mean in the right model (potentially the best solution) as the baseline and compare it with three other models. In each of the plots, the samples on the right of zero, represent positive difference, i.e., the case when the baseline method (in our case the posterior in the right model) was better than the considered alternative. Apart from raw samples, let’s plot the mean of such distribution (and, intuitively, we should expect it to be larger than zero) and report the percentage of samples on the right from zero.
As expected, a well-specified Bayesian model performs the best. However, having “enough” data points one can use the data mean as well (or the misspecified model without off-diagonal terms in the covariance). An interesting question would be to check how this “enough” depends on the dimensionality of the problem.
Footnotes
Probably I shouldn’t have, but I had to use a sparse prior over the space of positive definite matrices and I don’t know how to run Hamiltonian Monte Carlo with these choices…↩︎