Markov chain got stuck in a single mode? Parallel tempering comes to help.
Author
Paweł Czyż
Published
September 1, 2024
I have revived my interest in Ising models, which can be now trained using discrete Fisher divergence. However, once the model is trained, I would like to generate synthetic samples and evaluate the quality of the fit.
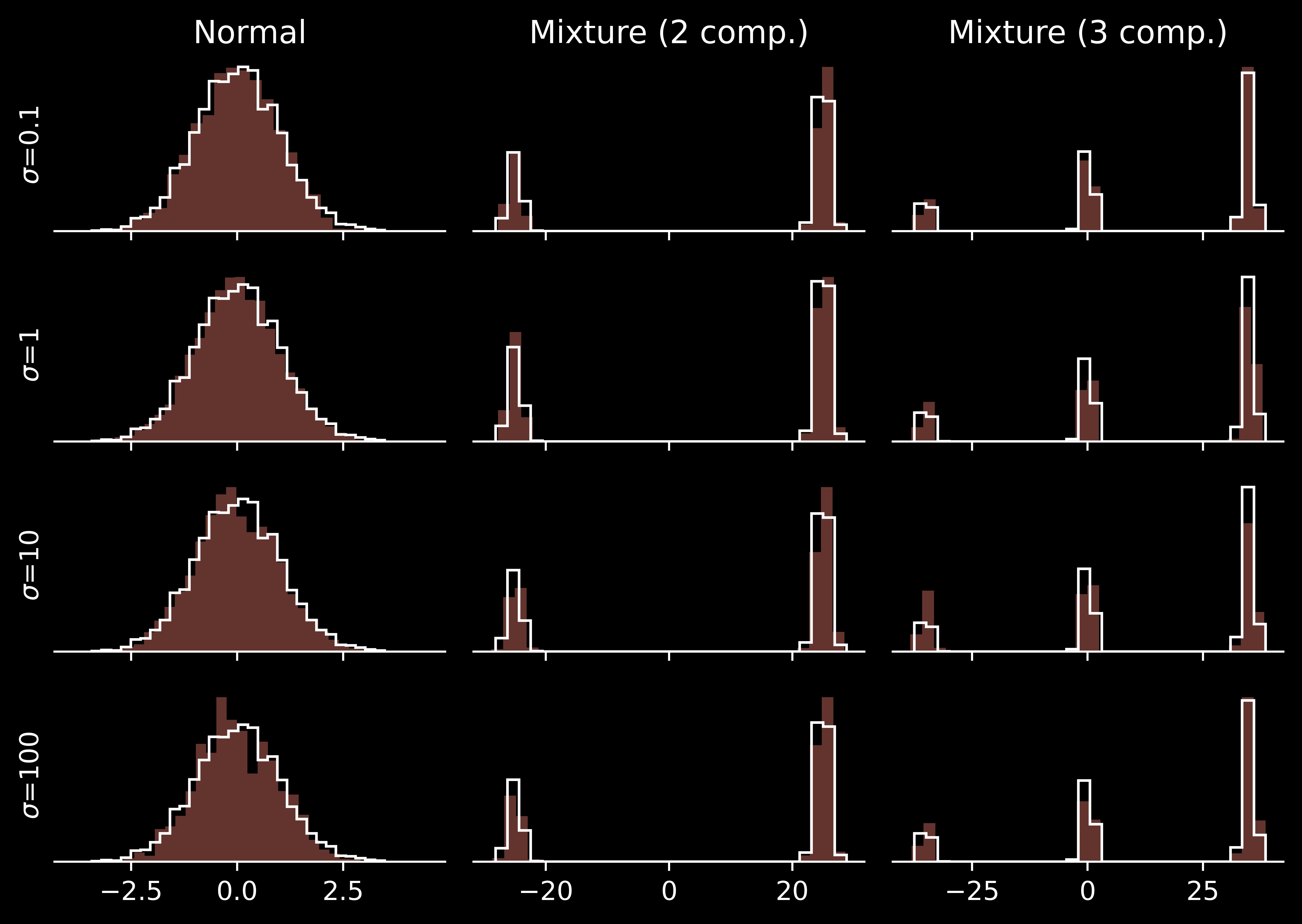
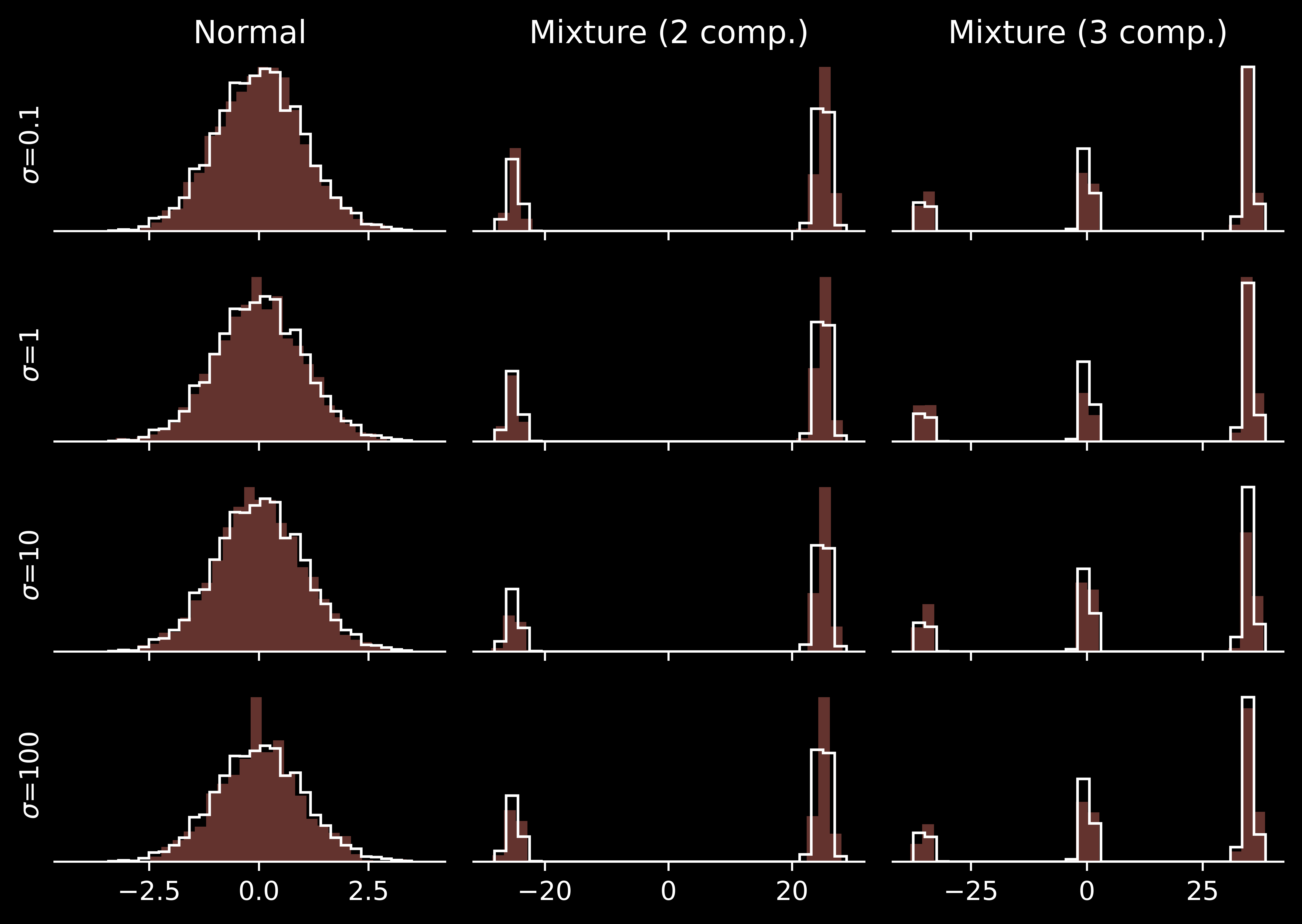
The standard solution for sampling from such distributions is our usual suspect, Markov chain Monte Carlo (MCMC). However, MCMC can get “trapped” in a single mode of the distribution and never escape it within the (finite) simulation time. Ising models are somewhat hard to visualise, so let’s focus on some one-dimensional problem and the simple Metropolis algorithm with Gaussian random walk proposals, namely \(q(x'\mid x) = \mathcal N\!\left(x' \mid x, \sigma^2\right)\).
We can use MCMC to obtain samples for the following problems:
Code
import numpy as npimport jaximport jax.random as jrandomimport jax.numpy as jnpfrom jaxtyping import Float, Int, Arrayimport numpyroimport numpyro.distributions as distimport matplotlib.pyplot as pltplt.style.use("dark_background")from typing import Anyfrom collections import OrderedDictRandomKey = jax.ArrayKernel =callable# kernel(key, x) -> new_xKernelParam = Anyclass JAXRNG:"""JAX stateful random number generator. Example: key = jax.random.PRNGKey(5) rng = JAXRNG(key) a = jax.random.bernoulli(rng.key, shape=(10,)) b = jax.random.bernoulli(rng.key, shape=(10,)) """def__init__(self, key: RandomKey) ->None:""" Args: key: initialization key """self._key = key@propertydef key(self) -> RandomKey:"""Generates a new key.""" key, subkey = jax.random.split(self._key)self._key = keyreturn subkeydef__repr__(self) ->str:"""Used by the repr() method."""returnf"{type(self).__name__}(key={self._key})"def__str__(self) ->str:"""Used by the str() method."""returnrepr(self)def mcmc_sampling_loop( key: RandomKey, x0: Float[Array, " *dim"], kernel: Kernel, n_samples: int, warmup: int=2_000,) -> Float[Array, "n_samples *dim"]:"""Markov chain Monte Carlo sampling loop."""def f(x, subkey): x_new = kernel(subkey, x)return x_new, x_new key_warmup, key_sampling = jrandom.split(key)# Run warm-up: update the starting point, but do not collect samples: x0, _ = jax.lax.scan(f, x0, jrandom.split(key_warmup, warmup))# Collect the samples: _, samples = jax.lax.scan(f, x0, jrandom.split(key_sampling, n_samples))return samplesdef sample_exact( key: RandomKey, distributions: OrderedDict, n_samples: int,) -> Float[Array, "n_distributions n_samples"]:"""Samples from the ground-truth distributions using (exact) ancestral sampling in NumPyro. Args: key: JAX random key distributions: an ordered dictionary mapping names to distribution factories. For example, `OrderedDict({"name": factory})`, where `factory()` returns a NumPyro distribution. n_samples: number of samples to collect """ xs_all = np.empty((len(distributions), n_samples))for idx, (_, dist_factory) inenumerate(distributions.items()): key, subkey = jrandom.split(key) distrib = dist_factory() xs = distrib.sample(subkey, sample_shape=(n_samples,)) xs_all[idx, :] = np.array(xs)return xs_alldef make_multirun( key: RandomKey, sampling_fn, distributions: OrderedDict, params: list,) -> Float[Array, "params distributions *samples"]:"""This function applies a sampling function over all distributions and parameters. Args: sampling_fn: function used to provide samples. It has the signature sampling_fn(key, log_prob, param) -> Float[Array, " *samples"] where "*samples" encodes all the dimension of the sample """ all_samples = []for param in params: samples_param = []for _, dist_factory in distributions.items():# Define log-PDFdef log_p(x): distribution = dist_factory()return distribution.log_prob(x) key, subkey = jrandom.split(key) samples = np.array(sampling_fn(key, log_p, param))# Append the samples samples_param.append(samples)# Now add the row all_samples.append(np.array(samples_param))return np.array(all_samples)def mcmc_multirun( key: RandomKey, kernel_generator, distributions: OrderedDict, params: list[KernelParam], n_samples: int, warmup: int, x0: float=0.5) -> Float[Array, "params distributions n_samples"]:"""A high-level function running an array of MCMC samplers over different distributions and parameter settings. """def sampling_fn(key, log_prob, param): kernel = kernel_generator(log_prob, param)return mcmc_sampling_loop( key=key, x0=jnp.asarray(x0), kernel=kernel, n_samples=n_samples, warmup=warmup )return make_multirun( key=key, sampling_fn=sampling_fn, distributions=distributions, params=params )
/home/pawel/micromamba/envs/data-science/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
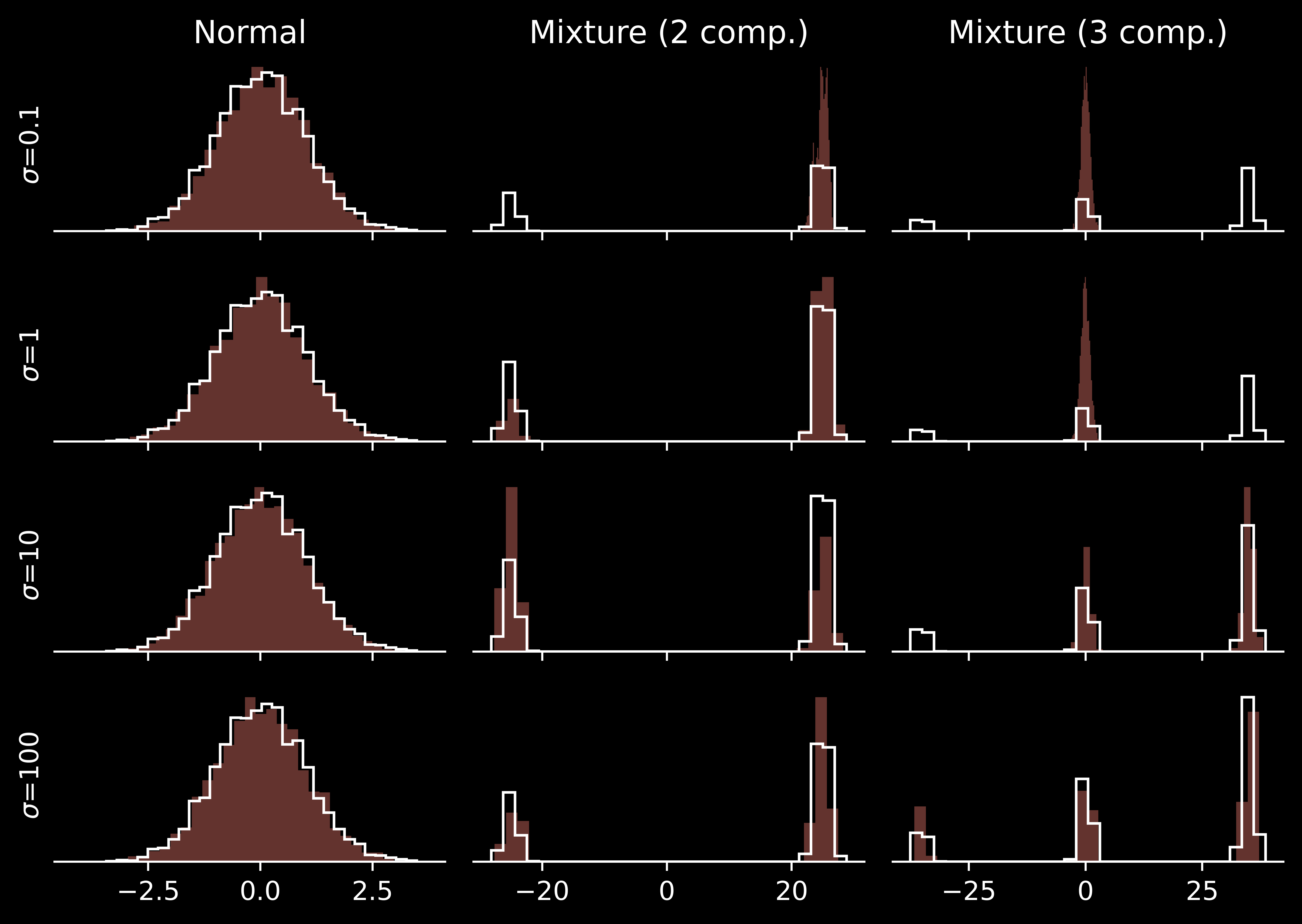
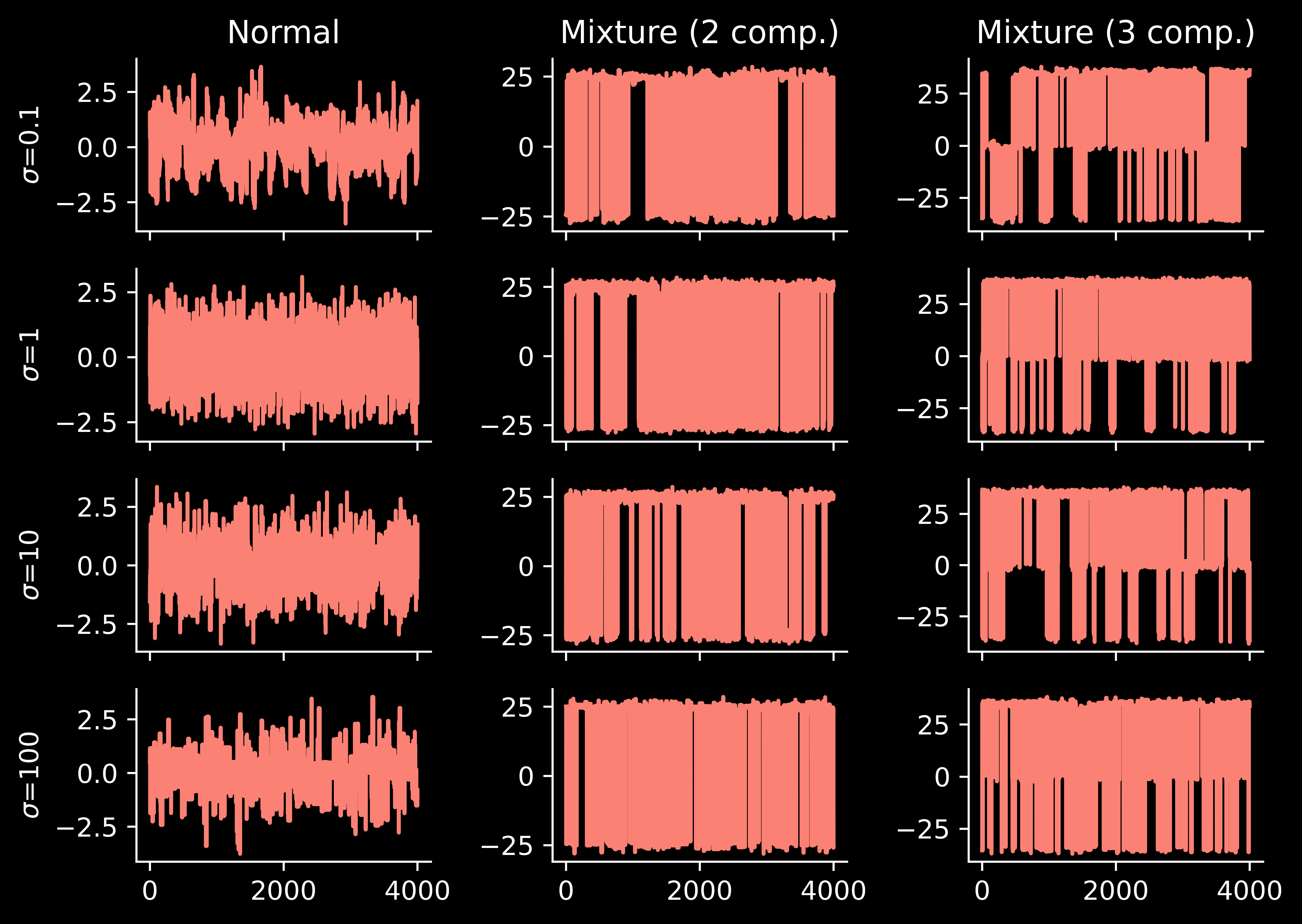
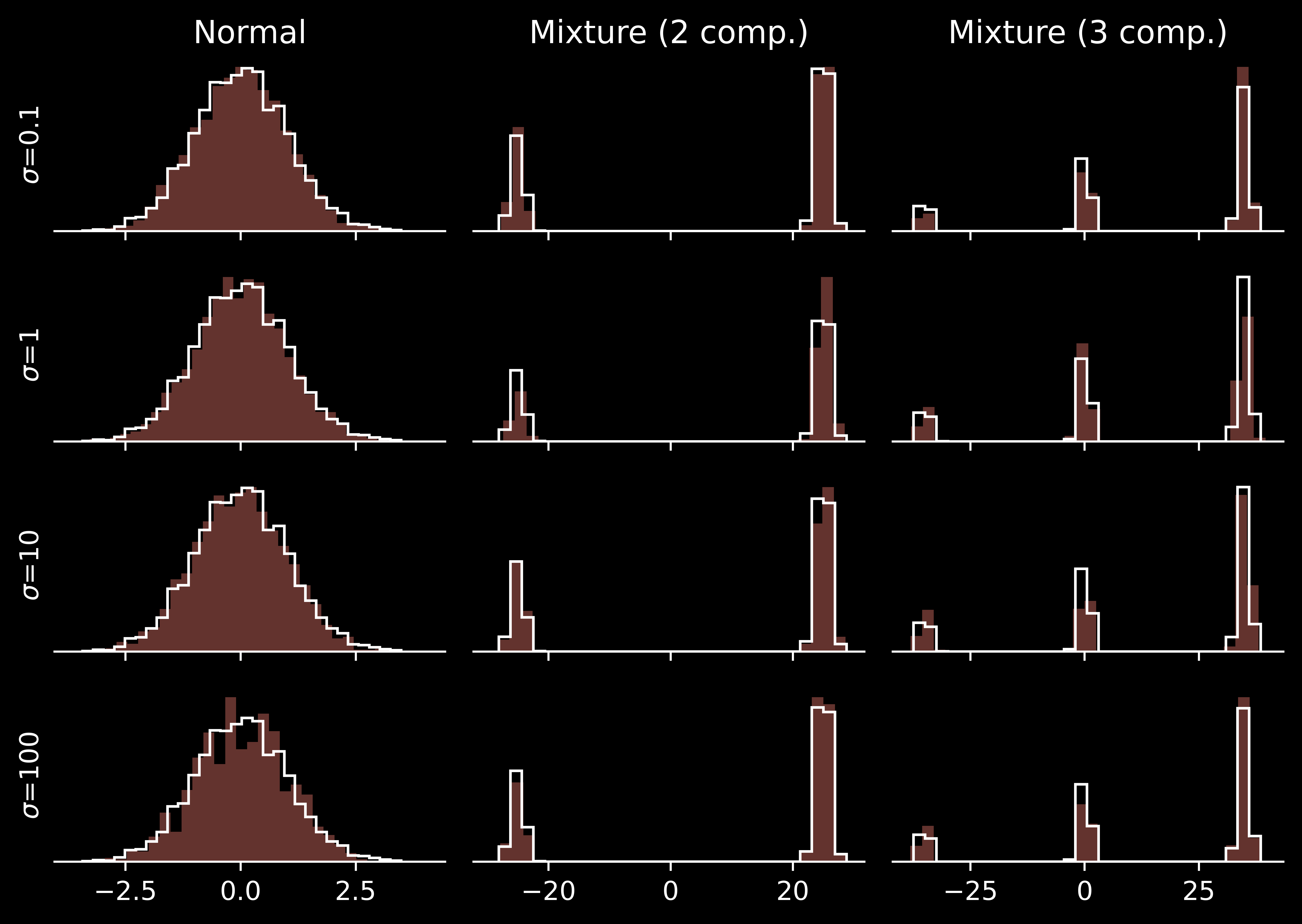
Too small \(\sigma\) results in large autocorrelation, making the effective sample size limited.
Medium \(\sigma\) can explore a single mode effectively. However, they cannot travel reasonably often switch between the modes and attribute wrong posterior probabilities to them.
Large \(\sigma\) allow one to switch between the modes quite often. However, for the simplest unimodal problem they suffer from low acceptance rate: many proposals are rejected.
Perfectly, we would use a sampling scheme allowing for both efficient local exploration and frequent jumps between the modes. There are different reasonable strategies:
We could devise a better kernel by using e.g., compositions or mixtures of kernels with different \(\sigma\). Or use a more sophisticated strategy of combining kernels, such as delayed rejection of P.J. Green and A. Mira (2001).
When working with continuous distributions defined on Euclidean spaces (which is the case here, but not for sampling from the Ising model), we could consider novel diffusion-based techniques such as the ones proposed by X. Huang et al. (2024) or L. Grenioux et al. (2024).
Use sequential Monte Carlo (SMC) samplers, as in the BlackJAX sampling book or this talk from Nicholas Chopin. SMC samplers can be used on any space, provided that one has efficient locally-exploring kernels.
Another solution (historically existing before the SMC samplers) is to use parallel tempering, which dates back to a 1991 paper of Charles Geyer, then termed \((MC)^3\), i.e., Metropolis-coupled Markov chain Monte Carlo.
Today we focus on the last method and look at a new variant of it.
Parallel tempering as originally designed
Consider a space \(\mathcal X\) with a probability distribution of interest \(p\) (by abuse of notation we write \(p\) both for the probability distribution and for its density with respect to some convenient measure on \(\mathcal X\)). We have a Markov kernel \(K\) allowing us to explore \(\mathcal X\) locally, but which has a trouble to pass through low-density regions separating distinct modes.
This issue can be addressed by extending the original space \(\mathcal X\) to a larger space \(\mathcal X^{N+1} = \mathcal X \times \cdots \times \mathcal X\) and targeting a product distribution \(\mathbf{p}(\mathbf x) = p_0(x_0)\cdots p_{N-1}(x_{N-1}) p_{N}(x_N)\), where \(p_N = p\) is the original distribution of interest and \(p_0, \dotsc, p_{N-1}\) are auxiliary distributions, designed to be easier to sample from. The main idea is that \(p_0\) should be chosen so that it is known to be easy to sample (e.g., i.i.d. samples are easy to generate) and the consecutive distributions, \(p_{i}\) and \(p_{i+1}\), should be closely related: the separate modes of \(p = p_N\) can be then “connected” by going through \(p_{N-1}, p_{N-2}, \dotsc\) to \(p_0\), which is then to sample from, and back.
For example, a typical choice for a sequence \(p_0, \dotsc, p_N=p\) is to use an annealing schedule \(0 = \beta_0 < \beta_1 < \dotsc < \beta_N = 1\) and employ the following distribution: \[
p_n(x) = \frac{1}{\mathcal Z(\beta_n)} \left(\frac{p(x)}{p_0(x)}\right)^{\beta_n} p_0(x) = \frac{1}{\mathcal Z(\beta_n)} p(x)^{\beta_n} p_0(x)^{1-\beta_n}
\]
Similarly as in SMC samplers, the schedule does matter a lot, controlling how much consecutive distributions are related. However, there is an important difference between SMC samplers and parallel tempering: they are orthogonal to each other, in the sense that parallel tempering at any single time keeps the states at across all the temperatures, while SMC samplers always have all the particles at the same temperature, which then rises over time. (I think this observation was made by Nicholas Chopin in one of his lecture, although I can’t find the exact reference. Many apologies for misquoting or misattributing this statement)
A Markov chain is now defined on \(\mathcal X^{N+1}\), with a state \(\mathbf{x} = (x_0, \dotsc, x_N)\). We consider two transitions:
Applying Markov kernels \(K_n\) to entries \(x_i\), targeting distributions \(p_i\), so that we do local exploration.
Swapping entries \(x_{i}\) with \(x_{i+1}\), so that we can eventually pass from \(x_N\) (which is targeting \(\pi\)) to \(x_0\) (which is easy to explore) and back.
Note that if the second kind of moves were not allowed, we would have just \(N+1\) independent Markov chains (each defined on the space \(\mathcal X\)) and targeting the \(\mathbf{p}\) distribution “individually”: the first chain would be efficient (exploring \(p_0\)) and the last one would mix very, very slow. As the chains are coupled, they are not individually Markov anymore and they travel between different tempered distributions (hopefully eventually reaching the same distribution). We can use them then to extract samples just from the \(p=p_N\) distribution.
To ensure that the Markov chain on \(\mathcal X^{N+1}\) explores \(\mathbf{p}\) properly, Charles Geyer proposed to swap components \(i\) and \(j\) according to a Metropolis update. If \(\mathbf{x}\) is the current state and \(\mathbf{x}'\) is the state with entries \(i\) and \(j\) swapped, the Metropolis ratio is given by \[
r(i, j) = \frac{ \mathbf{p}(\mathbf x')}{ \mathbf{p}(\mathbf x)} = \frac{ p_i(x_j) p_j(x_i)}{ p_i(x_i) p_j(x_j)}.
\]
Typically, only adjacent indices are swapped, as for \(i\) very distant from \(j\) we expect that \(r\) would close to zero. It is also informative to write this ratio in terms of the target and the reference distributions. As \(\log p_n(x) = \beta_n \log p(x) + (1-\beta_n) \log p_0(x) - \log \mathcal Z(\beta_n)\), we have \[\begin{align*}
\log r &= \beta_i (\log p(x_j) - \log p(x_i)) + (1-\beta_i) (\log p_0(x_j) - \log p_0(x_i)) \\
&+ \beta_j( \log p(x_i) - \log p(x_j) ) + (1-\beta_j)( \log p_0(x_i) - \log p_0(x_j) ) \\
&= -(\beta_i - \beta_j) \left( \log \frac{p(x_i)}{p_0(x_i)} - \log \frac{p(x_j)}{p_0(x_j)} \right)
\end{align*}
\]
This is a very convenient formula if \(p_0\) corresponds to the prior distribution and \(p\) is the posterior distribution, as their ratio is then simply the likelihood1.
This is enough theory for now – let’s implement parallel tempering in JAX.
JAX implementation
We need to make some design choices. We keep the state \(\mathbf{x} = (x_0, \dotsc, x_N)\) as a matrix \((N+1)\times (\mathrm{dim}\, \mathcal X)\). As we have access to two log-probability functions (\(p = p_N\) and the reference distribution \(p_0\)), we need to construct intermediate log-probability functions given an annealing schedule \(0 = \beta_0 < \beta_1 < \cdots < \beta_N\). To make everything vectorisable, let’s construct the individual kernels \(K_n\) as \(K_n = \mathcal{K}(\phi_n)\) using a factory function \(\mathcal{K}\) and kernel-specific parameters \(\phi_n\).
Hence, this implementation is not as general as possible, but it should be compatible with JAX vectorised operations.
To swap the chains, we do a “full sweep”, attemping to swap \(x_0 \leftrightarrow x_1\), then \(x_1\leftrightarrow x_2\), and up to \(x_{N-1}\leftrightarrow x_N\). This choice is actually important, as we will later see.
Code
def generate_independent_annealed_kernel( log_prob, log_ref, annealing_schedule, kernel_generator, params,) ->tuple:"""Generates the kernels via the kernel generator given appropriate parameters. Args: log_prob: log_prob of the target distribution log_ref: log_prob of the easy-to-sample reference distribution annealing_schedule: annealing schedule such that `annealing_schedule[0] = 0.0` and `annealing_schedule[-1] = 1` kernel_generator: `kernel_generator(log_p, param)` returns a transition kernel of signature `kernel(key, state) -> new_state` params: parameters for the transition kernels. Note that `len(annealing_schedule) = len(params)` """iflen(annealing_schedule) !=len(params):raiseValueError("Parameters have to be of the same length as the annealing schedule") n_chains =len(annealing_schedule)def transition_kernel(key, state, beta, param):def log_p(y):return beta * log_prob(y) + (1.0- beta) * log_ref(y)return kernel_generator(log_p, param)(key, state)def kernel(key, state_joint): key_vec = jrandom.split(key, n_chains)return jax.vmap(transition_kernel, in_axes=(0, 0, 0, 0))(key_vec, state_joint, annealing_schedule, params)return kerneldef generate_swap_chains_decision_kernel( log_prob, log_ref, annealing_schedule,):def log_p(y, beta):return beta * log_prob(y) + (1.0- beta) * log_ref(y)def swap_decision(key, state, i: int, j: int) ->bool: beta1, beta2 = annealing_schedule[i], annealing_schedule[j] x1, x2 = state[i], state[j] log_numerator = log_p(x1, beta2) + log_p(x2, beta1) log_denominator = log_p(x1, beta1) + log_p(x2, beta2) log_r = log_numerator - log_denominator r = jnp.exp(log_r)return jrandom.uniform(key) < rreturn swap_decisiondef generate_full_sweep_swap_kernel( log_prob, log_ref, annealing_schedule,):"""Applies a full sweep, attempting to swap chains 0 <-> 1, then 1 <-> 2 etc. one-after-another. """ n_chains =len(annealing_schedule)if n_chains <2:raiseValueError("At least two chains are needed.") swap_decision_fn = generate_swap_chains_decision_kernel( log_prob=log_prob, log_ref=log_ref, annealing_schedule=annealing_schedule, )def kernel(key, state):def f(state, i: int): subkey = jrandom.fold_in(key, i) decision = swap_decision_fn(subkey, state=state, i=i, j=i+1)# Candidate state: we swap values at i and i+1 positions swapped_state = state.at[i].set(state[i+1]) swapped_state = swapped_state.at[i+1].set(state[i]) new_state = jax.lax.select(decision, swapped_state, state)return new_state, None final_state, _ = jax.lax.scan(f, state, jnp.arange(n_chains -1))return final_statereturn kerneldef compose_kernels(kernels: list):"""Composes kernels, applying them in order."""def kernel(key, state):for ker in kernels: key, subkey = jrandom.split(key) state = ker(subkey, state)return statereturn kernel
We need also some annealing schedules:
Code
def annealing_constant(n_chains: int, base: float=1.0):"""Constant annealing schedule, should be avoided."""return base * jnp.ones(n_chains)def annealing_linear(n_chains: int):"""Linear annealing schedule, should be avoided."""return jnp.linspace(0.0, 1.0, n_chains)def annealing_exponential(n_chains: int, base: float=2.0**0.5):"""Annealing parameters form a geometric series (apart from beta[0] = 0). Args: n_chains: number of chains in the schedule base: geometric progression base, float larger than 1 """if base <=1:raiseValueError("Base should be larger than 1.")if n_chains <2:raiseValueError("At least two chains are required.")elif n_chains ==2:return jnp.array([0.0, 1.0])else: x = jnp.append(jnp.power(base, -jnp.arange(n_chains -1)), 0.0)return x[::-1]
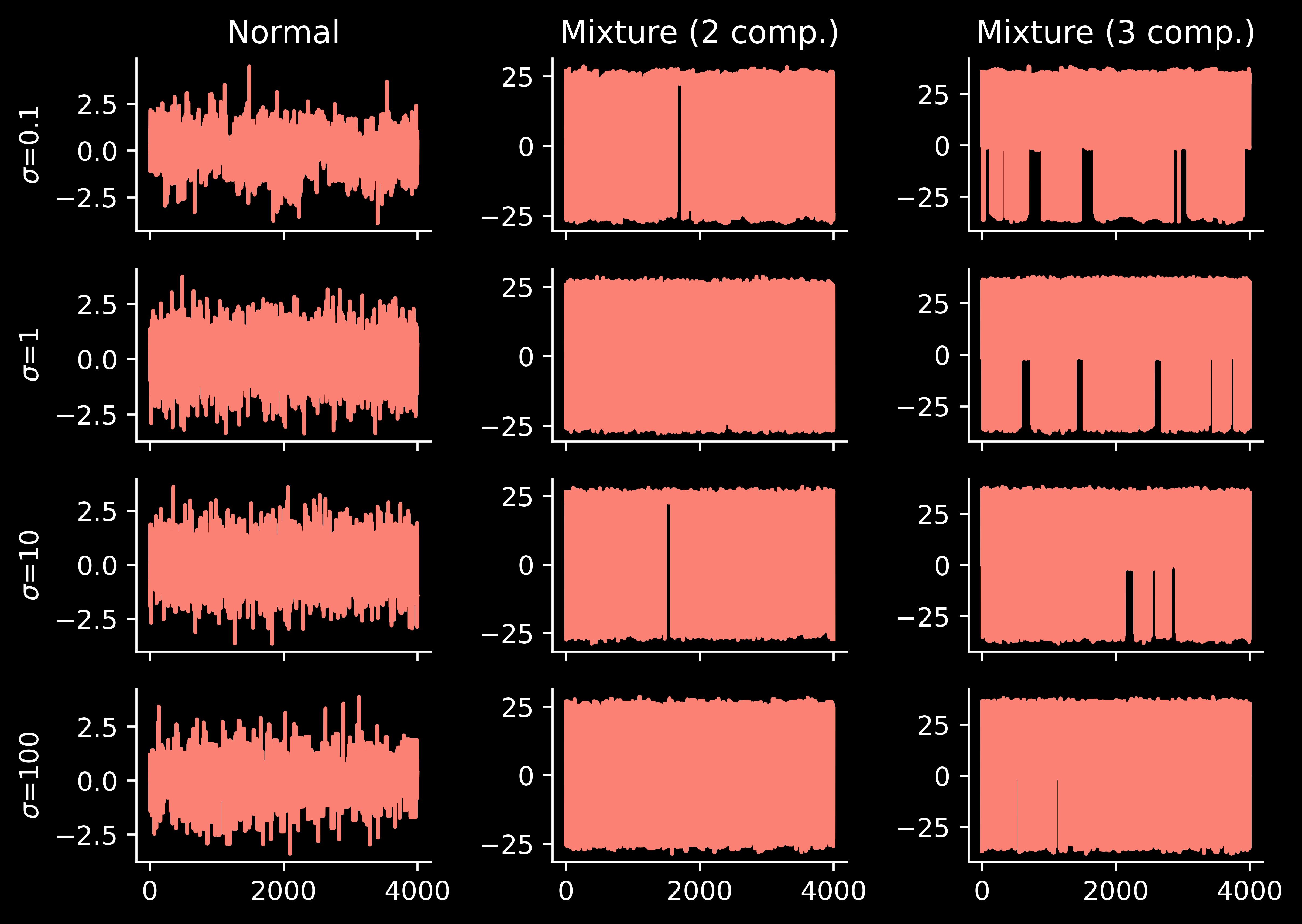
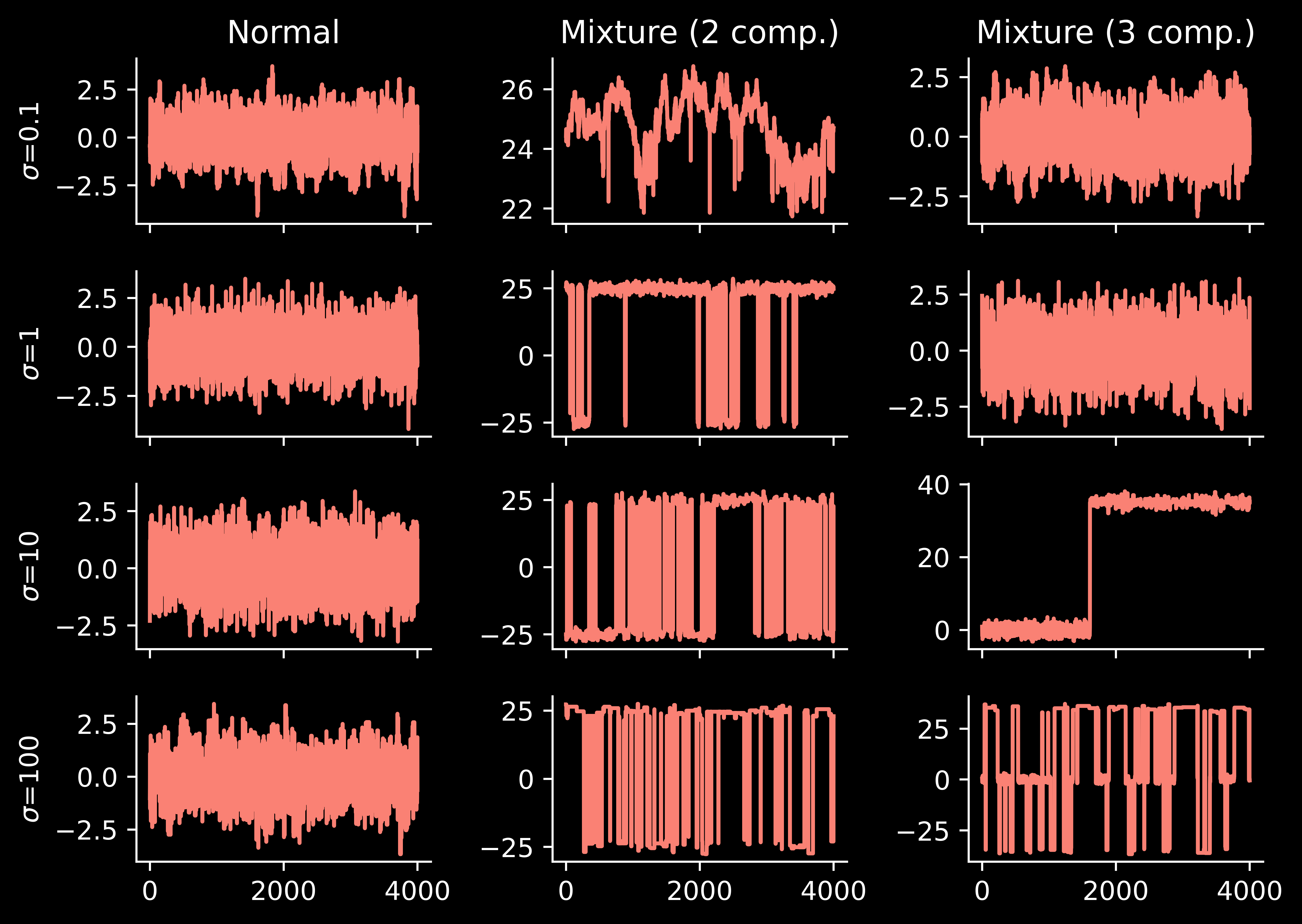
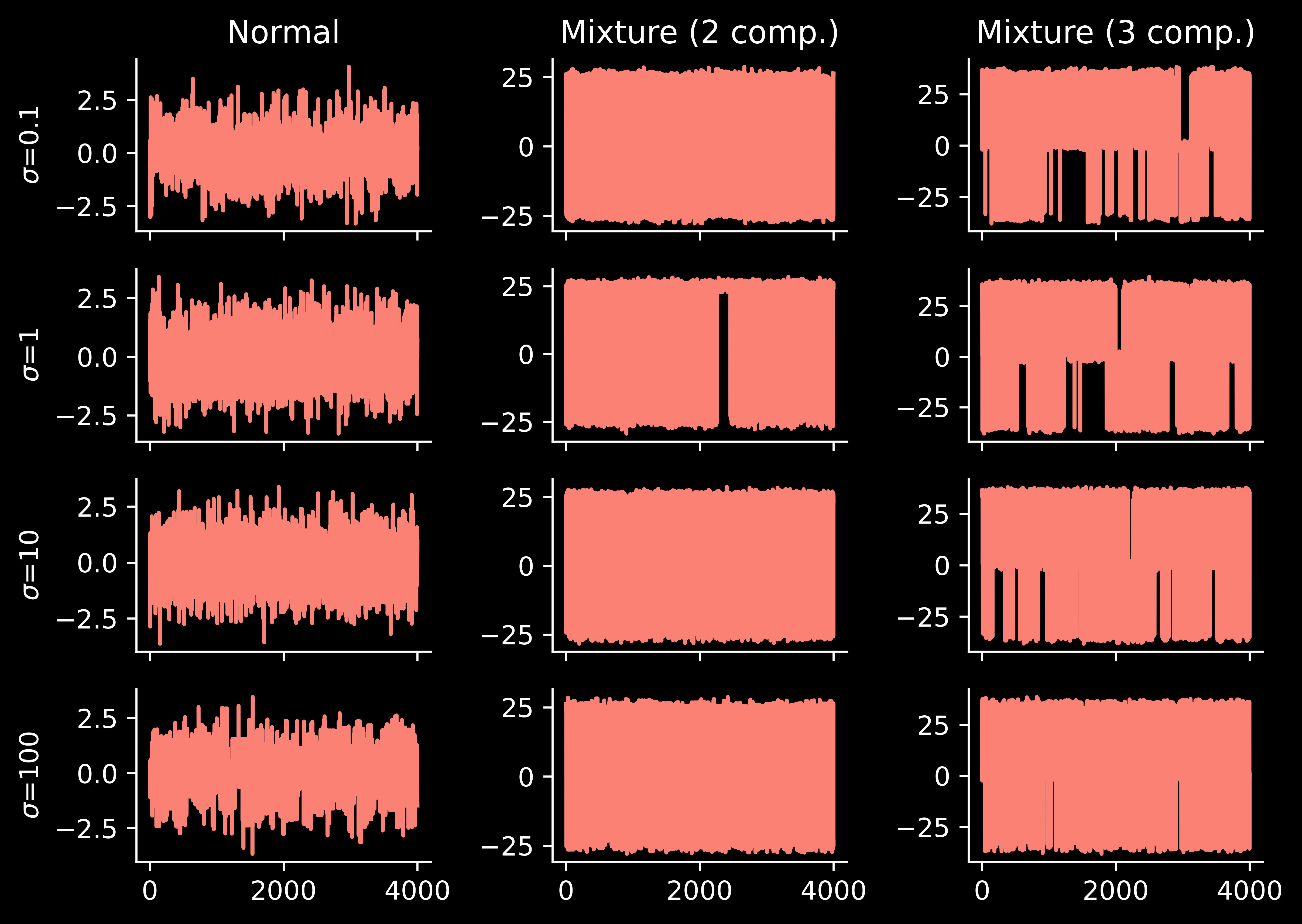
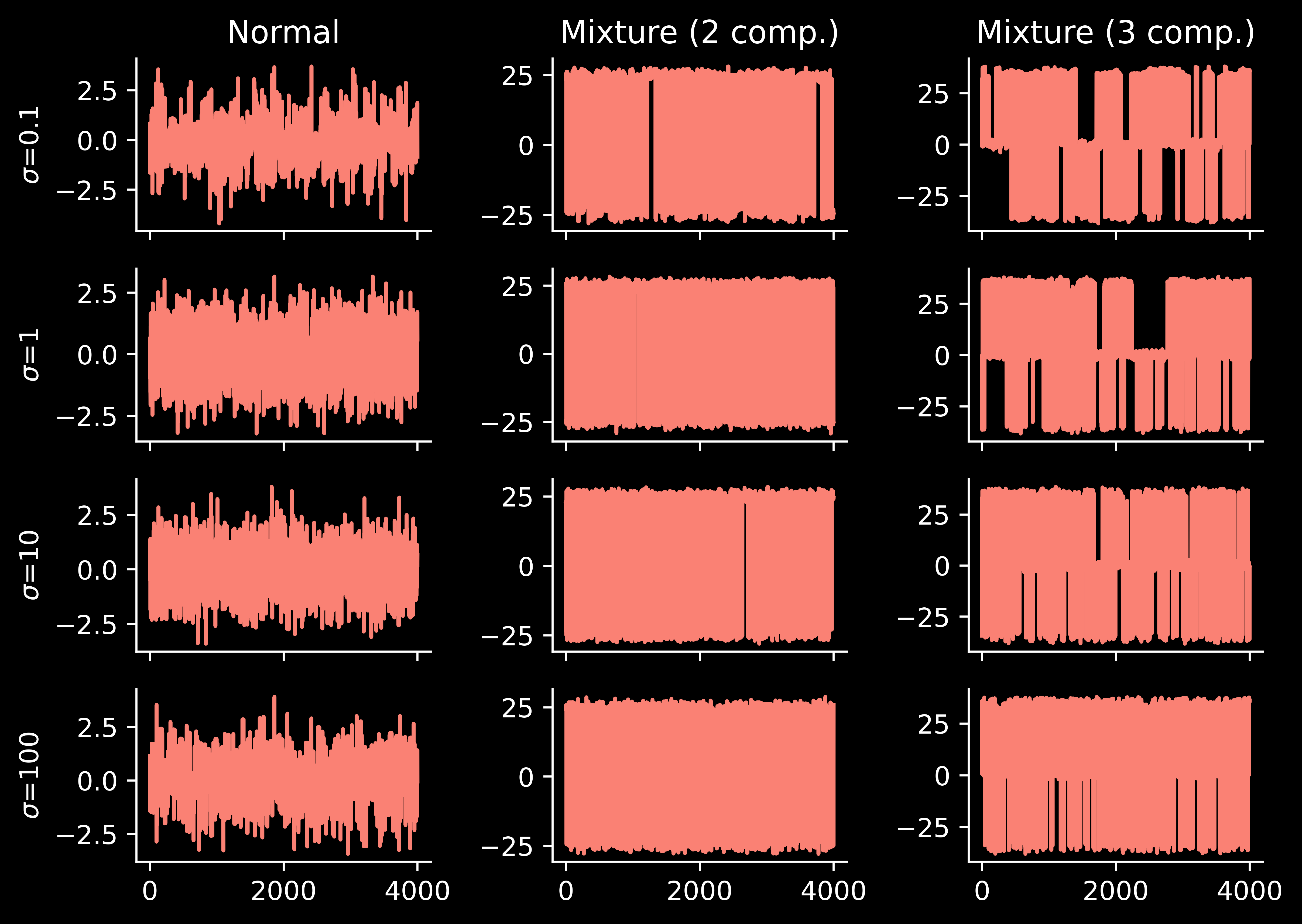
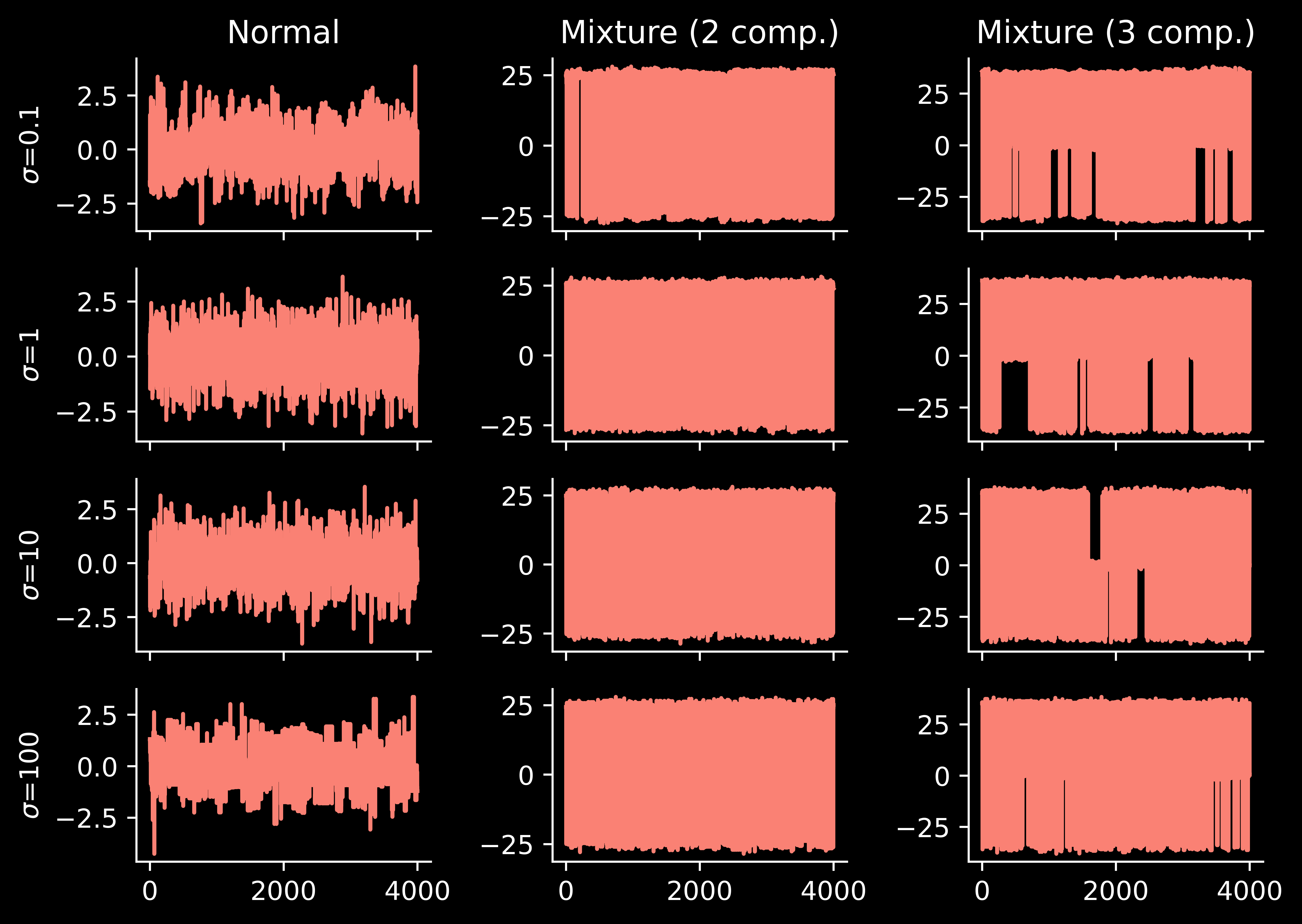
Now we can re-run the previous experiment, but with the usual random-walk MCMC replaced with parallel tempering:
Let’s understand parallel tempering better. The method has quite a few hyperparameters and we can understand what happens if we change them.
Reference distribution
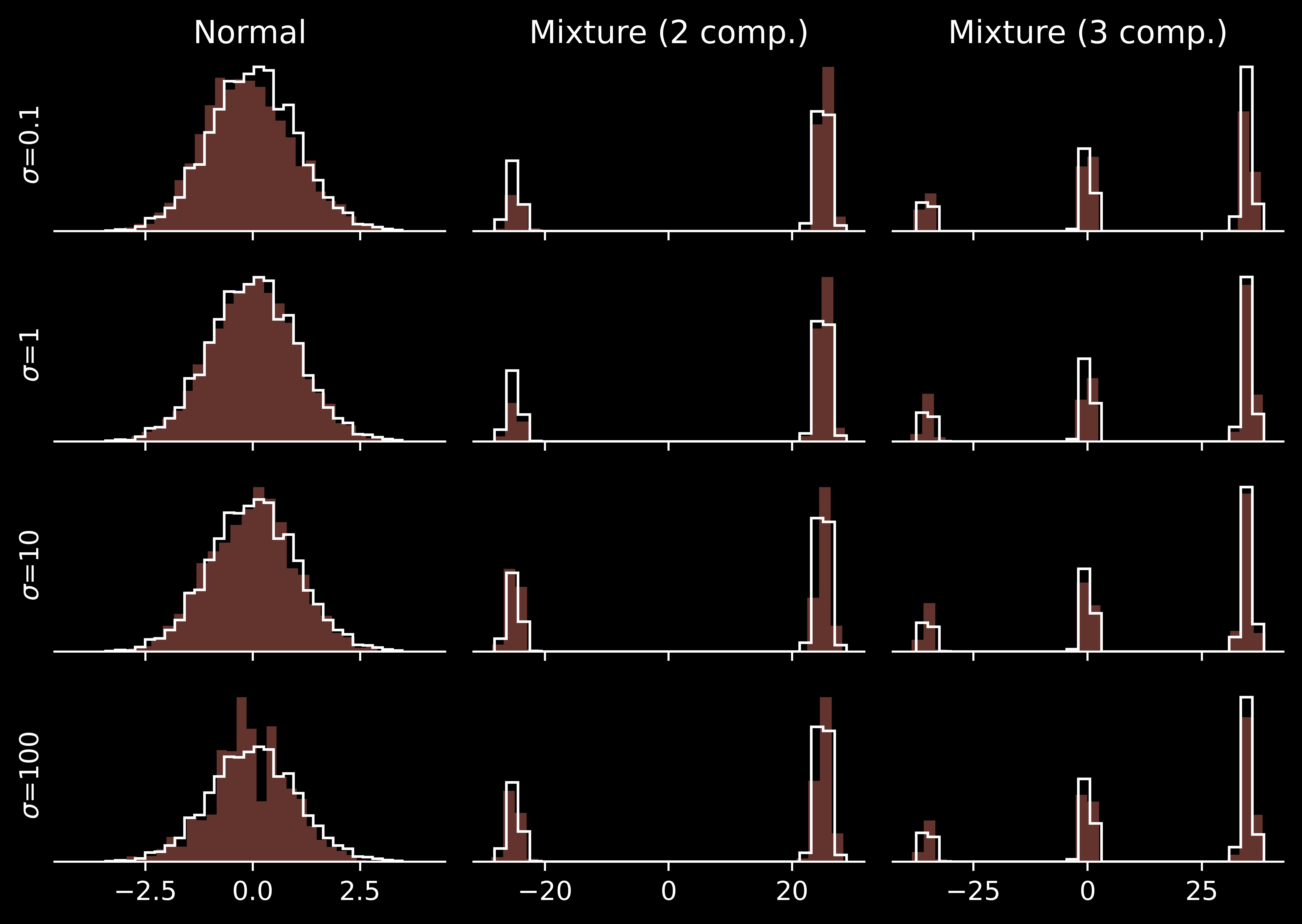
Consider a “too narrow” reference distribution, which puts low mass in the region where the modes of the target distribution arise (in the multimodal case).
… the behaviour of parallel tempering is somewhat better. Of course, not as good as when the reference \(p_0\) was closer to the target \(p=p_N\), but my current intuition is that it is better to use a “too wide” reference, rather than “too narrow”.
… we see excellent results. As we will see below, there exist parallel tempering schemes in which a large number of chains results in a bad performance. However, the “full sweep” variant does not seem to suffer from this issue. (I may need to revise this intuition one day, when precise theory is available, but right now I am happy with it).
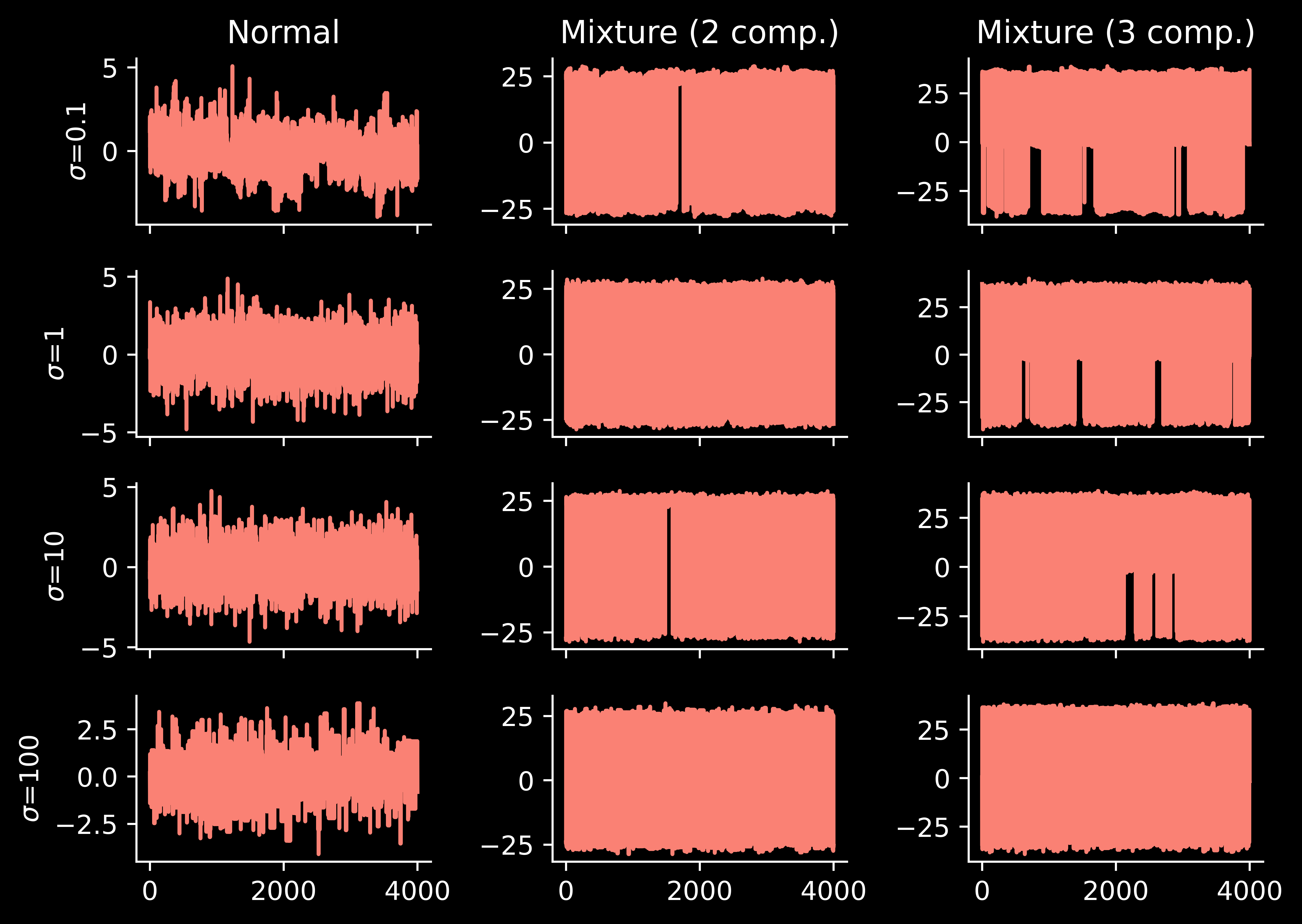
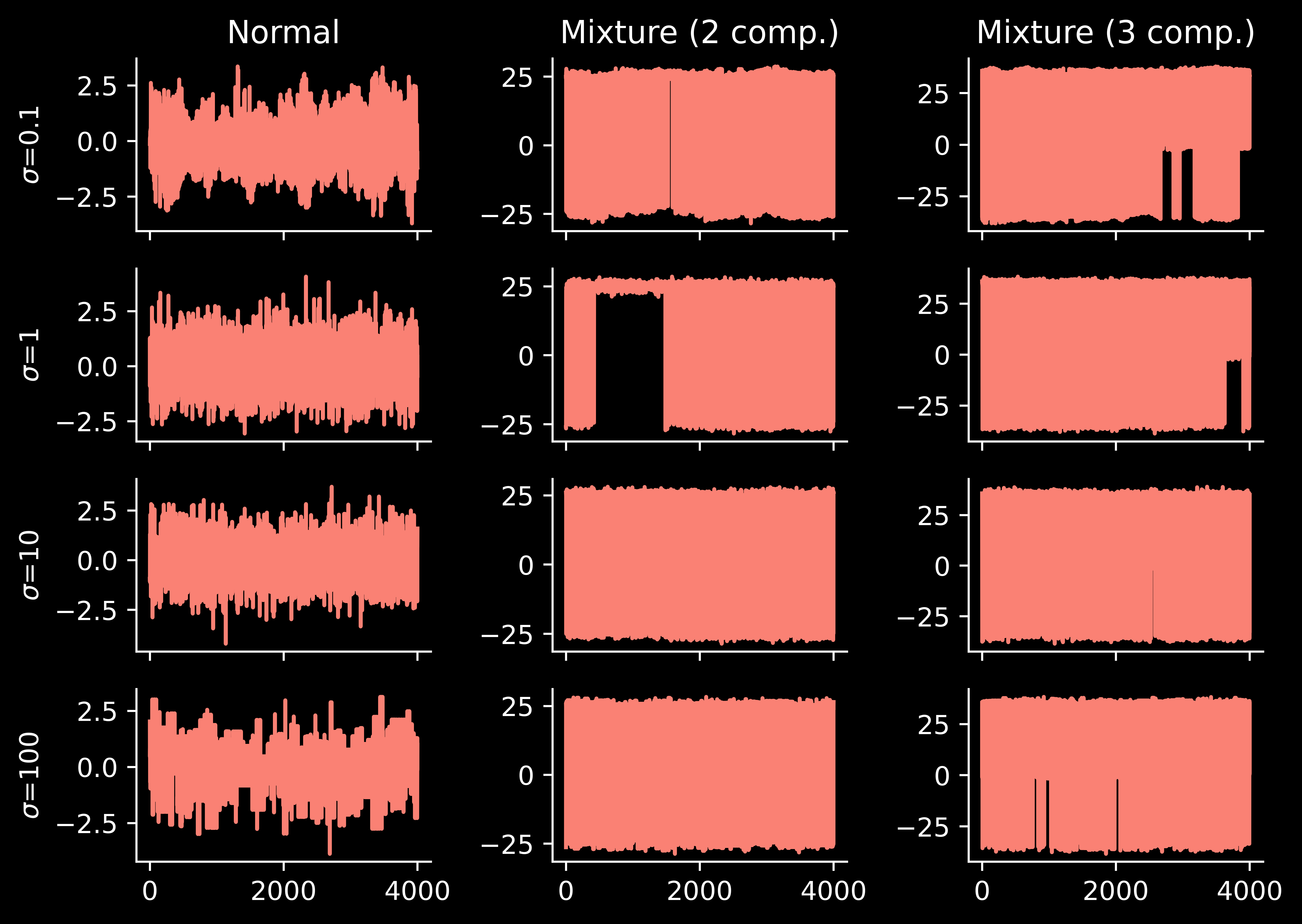
Annealing schedule
Finally, let’s take a look at the annealing schedule:
Code
for base in [1.01, 1.1, 1.2, 1.4]: schedule = np.asarray(annealing_exponential(n_chains=10, base=base)).tolist() schedule_str =", ".join(map(lambda x: f"{x:.1f}", schedule))print(f"{base}:\t{schedule_str}")
… the performance is reasonable. This is interesting.
Summary
My (current and subjective) intuition is that: - The most important thing is to ensure efficient sampling from the reference, \(p_0\), which should be somewhat close to \(p\). - It is better to use a bit “too wide” \(p_0\) rather than a “too narrow” one. - We need efficient local exploration. Parallel tempering can however improve on these aspects. - The annealing schedule and the number of chains also do matter. I feel that the points considered above may be a bit more important for the final performance than tuning the optimisation schedule (e.g., 10-20 chains and around 1.1-1.2 annealing constant seem to be quite reasonable defaults), but choosing the number of chains and annealing schedule properly does matter. Also, we can often easily change the number of chains and the annealing schedule, while changing \(p_0\) can be much more tricky (especially that in Bayesian inference problems, it often is taken to be the prior distribution, which cannot be changed arbitrarily).
These intuitions are based on “easy” low-dimensional problems considered above. However, for modern high-dimensional problems with many modes these intuitions may not generalise well. It is also much harder to ensure then that \(p_0\) is reasonably wide and that the kernels are efficient enough.
It would be nice to have a good default for the annealing schedule. Another aspect, which we do not consider above, but is important for very high-dimensional problems, is to use distributed computing on multiple machines or parallel computing on multiple cores. While it is easy to parallelise application of the kernels \(K_n\) to distinct components \(x_n\), our current “full sweep” swapping strategy has to be executed iteratively.
Consider a distributed swapping scheme in which we do not want to sequentially attempt swapping chains \(i \leftrightarrow i+1\) sequentially for all \(i=0, \dotsc, N-1\), but rather employ either an:
Even move: attempt swapping the states \(2k \leftrightarrow 2k+1\) (which can be done simultaneously for all \(k\) on different machines).
Odd move: attempt swapping the states \(2k-1 \leftrightarrow 2k\) (which also can be done simultaneously for all \(k\) on different machines).
Note that both moves are different from what we did above: each full sweep swapped the states consequtively. In particular, there was a chance (very small, though) to travel from \(p_0\) to \(p_N\) in one full sweep (incurring \(N-1\) swaps). Currently \(x_0\) can either be swapped with \(x_1\) (even move is accepted) or be left in place in one step (the odd move is executed or the even move is rejected).
The authors consider alternating between these moves basing on the following:
Stochastic even-odd swap (SEO): an unbiased coin is tossed to decide whether to execute the even or the odd move.
Deterministic even-odd swap (DEO): even time steps result in even moves and odd time steps result in odd moves.
It turns out that SEO is a very inefficient choice when a large number of chains is used and DEO is much more preferred (see also this section).
JAX implementation of DEO
Let’s implement DEO in JAX.
Our first task is to execute even and odd moves, which deserves a subsection on its own.
Controlled swapping problem
We have a state \(\mathbf{x} = (x_0, \dotsc, x_N)\) and we want to execute some moves. Let’s keep the information about the swaps in a binary mask matrix \(\mathbf{m} = (m_0, \dotsc, m_{N-1})\) such that \(m_i = 1\) if and only if we want to swap \(x_{i} \leftrightarrow x_{i+1}\) (and \(m_i = 0\) otherwise).
An even move in which (somewhat unlikely) all proposals are accepted has then a mask \(\mathbf{m}_\text{even} = (1, 0, 1, 0, \cdots)\) and an odd move has a mask \(\mathbf{m}_\text{odd} = (0, 1, 0, 1, \cdots)\). However, as only some moves have been accepted, some ones can be replaced by zeros. Namely, if we have a binary matrix \(\mathbf{m}_\text{accept}\), we have to take the entry-wise AND operation. For example, \(\mathbf{m} := \mathbf{m}_\text{accept}\, \&\, \mathbf{m}_\text{even}\) for accepted even moves.
Note that it is not possible to have two consecutive ones.
I find applying the swaps according to \(\mathbf{m}\) rather tricky. Consider the following algorithm:
y := [b, a] // i = 0, m[0] = 1
y := [b, b, c] // i = 1, m[1] = 0
The issue was that y[1] was updated both at i=0 and i=1 stages. Let’s think how we can improve this:
fn swapping_good(x[], m[]) -> y[]:
y := copy(x)
for i = 0, ..., N-1:
if m[i] = 1:
y[i] := x[i+1]
y[i+1] := x[i]
else: // m[i] = 0
y[i] := y[i] // Note that we do not change the values
y[i+1] := y[i+1] // simply copying them over
In this case, the algorithm works as following:
y = [a, b, c] // Before the loop
y = [b, a, c] // i = 0, m[0] = 1
y = [b, a, c] // i = 1, m[1] = 0
Let’s prove that this algorithm is indeed correct by showing that each y[i] attains the correct value. We consider three cases:
Case y[0]: we have y[0] := x[0] at the beginning. The only moment when it can be modified is at step i = 0. We have y[0] := y[0] = x[0] if m[0] = 0 and y[0] := x[0+1] = x[1] if m[0] = 1.
Case y[N]: similarly as above, y[N] := x[N] at the beginning and the only moment when it can be modified is at i = N-1 step. If m[N-1] = 0, then y[N] = x[N] and if m[N-1] = 1, then we overwrite the value to y[N] := x[N-1].
Case y[j] for 0 < j < N: at the beginning y[j] := x[j] and can be modified only at steps i=j-1 and i=j. We have three cases:
m[j-1, j] = [0, 0]. Then, y[j] = x[j] as it has not been modified at either step.
m[j-1, j] = [1, 0]. Then y[j] := x[j-1] at i=j-1 and stays unchanged at i=j, so in the end sequence we have y[j] = x[j-1].
m[j-1, j] = [0, 1]. Then, y[j] = x[j] at step i=j-1. Then, at step i=j we have y[j] := x[j+1].
Note that it is important that consecutive ones are not allowed.
Code
def _test_controlled_swapping(func): test_cases = [# Triples (x, m, y) ([1, 2], [0,], [1, 2]), ([1, 2], [1,], [2, 1]), ([1, 2, 3], [0, 0], [1, 2, 3]), ([1, 2, 3], [1, 0], [2, 1, 3]), ([1, 2, 3], [0, 1], [1, 3, 2]), ([1, 2, 3, 4], [1, 0, 1], [2, 1, 4, 3]), ([1, 2, 3, 4], [0, 1, 0], [1, 3, 2, 4]), ]for x, m, y in test_cases: y_ = func(jnp.asarray(x), jnp.asarray(m)) y_ = np.asarray(y_).tolist()iftuple(y_) !=tuple(y):raiseValueError(f"f(x={x}, m={m}) = {y_}. Expected {y}.")def controlled_swapping_scan( x: Float[Array, "n_chains *dims"], m: Int[Array, " n_chains-1"],) -> Float[Array, "n_chains *dims"]:"""Swaps the entries of `x`, as described by binary mask `m`. Args: x: array of shape (n_chains, dim) m: binary mask of shape (n_chains - 1,) controlling which chains should be swapped. We have `m[i] = 1` if `x[i]` and `x[i+1]` should be swapped. Note: Consecutive values 1 in `m` are not allowed. Namely, it cannot hold that `m[i] = m[i+1] = 1`. """def f(y, i): value = jax.lax.select(m[i], x[i +1], y[i]) # y[i] value_next = jax.lax.select(m[i], x[i], y[i +1]) # y[i + 1] y = y.at[i].set(value) y = y.at[i +1].set(value_next)return y, None# Run the scan over the range of M y, _ = jax.lax.scan(f, x, jnp.arange(m.shape[0]))return y_test_controlled_swapping(controlled_swapping_scan)
This implementation seems to work and shows how powerful [jax.lax.scan](https://jax.readthedocs.io/en/latest/_autosummary/jax.lax.scan.html) can be. However, JAX is built to accelerate linear algebra and perhaps we can come up with an appropriately vectorised operation. Let’s go through the three cases once again.
Case y[0]: we want x[0] if m[0] = 0 and x[1] if m[1] = 1. In other words, we have y[0] = x[m[0]].
Case y[N]: we want x[N-1] if m[N-1] = 1 and x[N] if m[N-1] = 0. Hence, y[N] = x[N - m[N-1]].
Case y[j] for 0 < j < N: as before, we have three cases, controlled by m[j-1] and m[j]. I claim that y[j] = x[j + m[j] - m[j-1]]. For both zeros, we do not swap anything and have y[j] = x[j]. For m[j-1, j] = [0, 1] we want to have y[j] = x[j+1] and for m[j-1, j] = [1, 0] we have y[j] = x[j-1].
The implementation is now trivial:
Code
def _create_indices(m): N = m.shape[0] +1 base_indices = jnp.arange(1, N-1) # Length N-2 ind_middle = base_indices + m[1:] - m[:-1] ind = jnp.concatenate(( jnp.array([m[0]]), ind_middle, jnp.array([N -1- m[-1]]) ))return inddef controlled_swapping( x: Float[Array, "n_chains *dims"], m: Int[Array, " n_chains-1"],) -> Float[Array, "n_chains *dims"]:"""Swaps the entries of `x`, as described by binary mask `m`. Args: x: array of shape (n_chains, dim) m: binary mask of shape (n_chains - 1,) controlling which chains should be swapped. We have `m[i] = 1` if `x[i]` and `x[i+1]` should be swapped. Note: Consecutive values 1 in `m` are not allowed. Namely, it cannot hold that `m[i] = m[i+1] = 1`. """ indices = _create_indices(m)return x[indices, ...]_test_controlled_swapping(controlled_swapping)
DEO swapping kernel and the sampling loop
At this stage, we can implement the swapping kernel. Note that this kernel has a different signature than usual, additionally taking the timestep as input and calculating the rejection rates, which will turn out to be useful when we optimise the annealing schedule. Due to the fact that the swaps are not “interfering”, we can use vectorised operations.
Code
def generate_deo_extended_kernel( log_prob, log_ref, annealing_schedule,):def log_p(y, beta):return beta * log_prob(y) + (1.0- beta) * log_ref(y) log_p_vmap = jax.vmap(log_p, in_axes=(0, 0))def extended_kernel( key, state, timestep: int, ) ->tuple:"""Extended deterministic even-odd swap kernel, which for even timesteps makes even swaps (2i <-> 2i+1) and for odd timesteps makes odd swaps (2i-1 <-> 2i) Args: key: random key state: state timestep: timestep number, used to decide whether to make even or odd move Returns: new_state, the same shape as `state` rejection_rates, shape (n_chains-1,) """ n_chains = state.shape[0] idx1 = jnp.arange(n_chains -1) idx2 = idx1 +1 xs1 = state[idx1] xs2 = state[idx2] betas1 = annealing_schedule[idx1] betas2 = annealing_schedule[idx2] log_numerator = log_p_vmap(xs1, betas2) + log_p_vmap(xs2, betas1) log_denominator = log_p_vmap(xs1, betas1) + log_p_vmap(xs2, betas2) log_accept = log_numerator - log_denominator accept_prob = jnp.minimum(jnp.exp(log_accept), 1.0) rejection_rates =1.0- accept_prob# Where the swaps would be accepted through M-H accept_mask = jrandom.bernoulli(key, p=accept_prob)# Where the swaps can be accepted due to even-odd moves even_odd_mask = jnp.mod(idx1, 2) == jnp.mod(timestep, 2) total_mask = accept_mask & even_odd_mask# Now the tricky part: we need to execute the swaps new_state = controlled_swapping(state, total_mask)return new_state, rejection_ratesreturn extended_kerneldef deo_sampling_loop( key: RandomKey, x0, kernel_local, kernel_deo, n_samples: int, warmup: int,) ->tuple:"""The sampling loop for DEO parallel tempering. Returns: samples rejection_rates """def f(x, timestep: int): subkey = jrandom.fold_in(key, timestep) key_local, key_deo = jrandom.split(subkey)# Apply local exploration kernel x = kernel_local(key_local, x)# Apply the DEO swap x, rejection_rates = kernel_deo( key_deo, x, timestep, )return x, (x, rejection_rates)# Run warmup x0, _ = jax.lax.scan(f, x0, jnp.arange(warmup))# Collect samples _, (samples, rejection_rates) = jax.lax.scan(f, x0, jnp.arange(n_samples))return samples, rejection_ratesdef nonreversible_pt_multirun_sigmas( key: RandomKey, sigmas: list[float], distributions: OrderedDict, n_samples: int, warmup: int, reference_scale: float=20.0, n_chains: int=10, schedule_const: float=1.1, x0: float=0.5, annealing_schedule: Float[Array, " n_chains"] =None,):if annealing_schedule isNone: betas = annealing_exponential(n_chains=n_chains, base=schedule_const)else: betas = jnp.asarray(annealing_schedule)def log_ref(x):return dist.Normal(0, reference_scale).log_prob(x)def sampling_fn(key, log_prob, sigma):# We know how to sample from the reference distribution sigmas = sigma * jnp.ones_like(betas) sigmas = sigmas.at[0].set(reference_scale) K_ind = generate_independent_annealed_kernel( log_prob=log_prob, log_ref=log_ref, annealing_schedule=betas, kernel_generator=generate_kernel, params=sigmas, ) K_deo = generate_deo_extended_kernel( log_prob=log_prob, log_ref=log_ref, annealing_schedule=betas, ) key, subkey = jrandom.split(key) samples, rejections = deo_sampling_loop( key=subkey, x0=x0 * jnp.ones(n_chains, dtype=float), kernel_local=K_ind, kernel_deo=K_deo, n_samples=n_samples, warmup=warmup, )return samplesreturn make_multirun( key, sampling_fn=sampling_fn, distributions=distributions, params=sigmas, )
Interestingly, DEO has better performance than SEO, which are termed in the paper, respectively, non-reversible and reversible parallel tempering schemes. The discussion whether to use non-reversible or reversible kernels has a long history and I still find the topic mysterious. Probably it is worth to write a separate blog post on the topic, but:
In a great 2016 paper from Gareth Roberts and Jeffrey Rosenthal there are examples where “systematic scan” Gibbs samplers (which often are non-reversible, although not always: recall palindromic kernels of the form \(K_1 K_2 K_1\)) can outperform “random scan” (always reversible) Gibbs samplers. Examples with the opposite behaviour are also provided.
In a 2016 C. Andrieu’s paper there is a theorem showing that for two kernels fulfilling some technical assumptions, systematic scans are more efficient than random ones. This could perhaps offer an orthogonal perspective on why DEO is more efficient than SEO, but I am not sure.
This discussion whether reversible or non-reversible scheme could be used is one way of looking at the problem. Another is through the perspective of reducing the diffusive random walk behaviour by introducing a momentum variable. Momentum is a common theme in computational statistics and machine learning, with examples such as MALA and Hamiltonian Monte Carlo in Markov chain Monte Carlo world or stochastic gradient descent with momentum in optimisation.
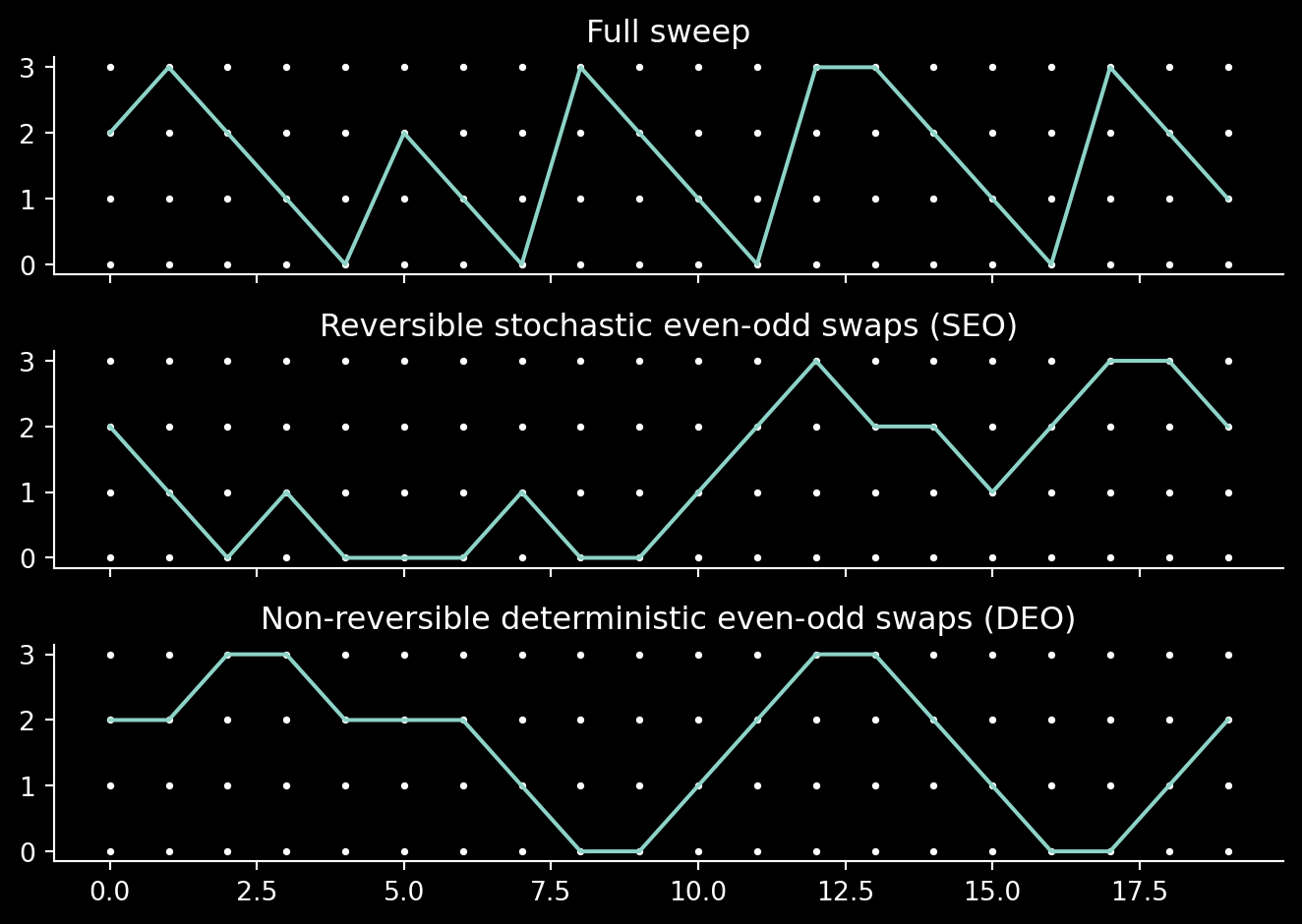
DEO reduces random walk in swapping the chains (which is studied through the perspective of an index process) and can be thought as of introducing a (discrete) momentum variable. I will skip the precise description of the index process, replacing it with a picture I based on the figures from the paper. We will simulate the path of the chain under the sequential scheme we studied before, SEO and DEO:
Code
def _find_trajectory(states, tracked: int=None): n_chains = states.shape[1]if tracked isNone: tracked = n_chains //2return jnp.einsum("ng,g->n", states == tracked, jnp.arange(n_chains))def generate_figure_momentum(p: float=0.85, n_chains: int=5, n_timesteps: int=30): rng = np.random.default_rng(8) fig, axs = plt.subplots(3, 1, sharex=True, sharey=True) x_axis = np.arange(n_timesteps)for ax in axs:for chain inrange(n_chains): ax.scatter(x_axis, chain * np.ones_like(x_axis), c="w", s=3) ax.spines[["top", "right"]].set_visible(False)# Sample full sweep state = jnp.arange(n_chains) states = [state]for timestep inrange(1, n_timesteps):for i inrange(n_chains -1):if rng.binomial(1, p): new_state = state.at[i].set(state[i+1]) new_state = new_state.at[i+1].set(state[i]) state = new_state states.append(state) states = jnp.stack(states) trajectory = _find_trajectory(states) ax = axs[0] ax.plot(x_axis, trajectory) ax.set_title("Full sweep")# Sample SEO state = jnp.arange(n_chains) states = [state]for timestep inrange(1, n_timesteps): mode = rng.binomial(1, 0.5)for i inrange(n_chains -1):if (i %2== mode) and rng.binomial(1, p): new_state = state.at[i].set(state[i+1]) new_state = new_state.at[i+1].set(state[i]) state = new_state states.append(state) states = jnp.stack(states) trajectory = _find_trajectory(states) ax = axs[1] ax.plot(x_axis, trajectory) ax.set_title("Reversible stochastic even-odd swaps (SEO)")# Sample DEO state = jnp.arange(n_chains) states = [state]for timestep inrange(1, n_timesteps):for i inrange(n_chains -1):if (i %2== timestep %2) and rng.binomial(1, p): new_state = state.at[i].set(state[i+1]) new_state = new_state.at[i+1].set(state[i]) state = new_state states.append(state) states = jnp.stack(states) trajectory = _find_trajectory(states) ax = axs[2] ax.plot(x_axis, trajectory) ax.set_title("Non-reversible deterministic even-odd swaps (DEO)") fig.tight_layout()return figfig = generate_figure_momentum(p=0.8, n_chains=4, n_timesteps=20)
Definitely, SEO has a trouble going between the reference and the target distribution. On the other hand, in these simulations (which are very simplistic, though!), DEO does not show a clear advantage over the full sweep (other than being more parallelisable). Note that both SEO and DEO can move an index only by \(\pm 1\), while the full sweep can increase the index arbitrarily. However, it also decreases the indices at most by \(1\). It may perhaps be interesting to consider a deterministic forward-backward full sweep scheme, in which even timesteps make a full forward sweep (as we did in the first prototype) and odd timesteps make a backward sweep.
I think studying the behaviour of the DEO scheme is an important contribution of this paper, but there several more:
By introducing and studying the index process, the authors devise the DEO sampling scheme together with a method for choosing the annealing schedule basing on preliminary runs.
The proposed sampling scheme is highly parallelisable and can be used in distributed computing environments. The experiments in the paper cover many complex high-dimensional distributions. Moreover, a new Julia package, Pigeons.jl makes application of non-reversible parallel tempering practical in the distributed setting.
Let’s see, however, how to tune the annealing schedule, which has a wonderful theory outlined in Section 4 of the paper.
Annealing schedule optimisation
Assuming efficient local exploration of individual components, the authors build a theory how quickly the chain can cycle between \(p_0\) and \(p=p_N\). The key quantity is the instateneous rejection rate function \[
\lambda(\beta) = \frac{1}{2} \mathbb E_{X, Y \sim_\mathrm{i.i.d.} p_\beta } \left[\left| \log \frac{ p(X) p_0(Y)}{ p(Y) p_0(X) } \right|\right],
\]
which depends on the annealing parameter \(\beta\) (which controls the measure over which we integrate), but also on how different \(p\) and \(p_0\) are. Define \[
\Lambda(\beta) = \int_{0}^{\beta} \lambda(\beta') \,\mathrm{d}\beta'.
\]
If \(\tilde \Lambda = \Lambda(1)\), then for small \(\max_i |\beta_i - \beta_{i+1}|\) it holds that the “round-trip rate”, describing how often going from \(p_0\) to \(p\) and back, for SEO is about \[
f_\mathrm{SEO} \approx \frac{1}{2N + 2\tilde \Lambda}.
\]
Using a large \(N\) for SEO leads to diffusive behaviour with close-to-zero round-trip rate! I find this result amazing. What is even more interesting, for DEO: \[
f_\mathrm{DEO} \approx \frac{1}{2 \cdot \left(1+\tilde \Lambda\right)}.
\]
DEO with large \(N\) does not have the diffusive behaviour, with the round-trip rate being controlled by the communication barrier\(\tilde \Lambda\), which depends on \(p_0\) and \(p\). Hence, for large \(\tilde\Lambda\) many, many iterations may be necessary to obtain enough round trips and good mixing.
Interestingly, the \(\Lambda\) function can be estimated from a run using a fine-grained annealing schedule. It turns out that if \(\rho(\beta, \beta')\) is the expected rejection rate of swapping the chains between \(\beta\) and \(\beta'\) (so that, of course, \(\rho(\beta, \beta') = \rho(\beta', \beta)\)), then \[
\rho(\beta, \beta') = | \Lambda(\beta) - \Lambda(\beta') | + O(|\beta - \beta'|^3).
\]
In particular, \[
\tilde \Lambda \approx \sum_{i=0}^{N-1} \rho(\beta_{i}, \beta_{i+1}),
\]
where the error is of order \(O\!\left(N \cdot \left(\max_i |\beta_i - \beta_{i+1}|\right)^3 \right)\).
In other words, \(\Lambda(\beta)\) can be estimated from the rejection probabilities.
To optimise the schedule, the authors note that the round-trip rate under DEO is given by \[
f = \frac{1}{2\left(1 + \sum_{i=0}^{N-1} \frac{\rho(\beta_{i}, \beta_{i+1})}{ 1-\rho(\beta_i, \beta_{i+1}) } \right)}
\]
for any schedule. (Note that the approximation of \(f_\mathrm{DEO}\) when differences \(|\beta_i - \beta_{i+1}|\) are small, can be read from this formula: all \(\rho\) are small, so we can ignore terms \(1-\rho\) and then we obtain \(\tilde \Lambda\)).
As we want to maximise \(f\), we need to find a schedule minimising the denominator. On the other hand, there is a constraint that for any fine-grained schedule it holds that
so that this is a constrained optimisation problem. It turns out that the optimum is attained when \(\rho(\beta_i, \beta_{i+1})\) are all equal. Using the relationship between \(\rho\) and differences in \(\Lambda\), we see that we should aim at \[
\Lambda(\beta_i) \approx \frac{i}{N} \tilde \Lambda.
\]
JAX implementation
Code
from scipy.interpolate import PchipInterpolatorfrom scipy.optimize import bisectdef estimate_lambda_values(rejection_rates, offset: float=1e-3):# Make sure that the estimated rejection rates are non-zero rejection_rates = jnp.maximum(rejection_rates, offset)# We have Lambda(0) = 0 and then estimate the rest by cumulative sums extended = jnp.concatenate((jnp.zeros(1), rejection_rates))return jnp.cumsum(extended)def get_lambda_function( annealing_schedule, lambda_values,):"""Approximates the Lambda function from several estimates at the schedule by interpolating the values with a monotonic cubic spline (as advised in the paper)."""return PchipInterpolator(annealing_schedule, lambda_values)def annealing_optimal( n_chains: int, previous_schedule, rejection_rates, _offset: float=1e-3,):"""Finds the optimal annealing schedule basing on the approximation of the Lambda function.""" lambda_values = estimate_lambda_values(rejection_rates, offset=_offset) lambda_fn = get_lambda_function( previous_schedule, lambda_values, ) lambda1 = lambda_values[-1] new_schedule = [0.0]for k inrange(1, n_chains -1):def fn(x): desired_value = k * lambda1 / (n_chains -1)return lambda_fn(x) - desired_value new_point = bisect( fn, new_schedule[-1],1.0, )if new_point >=1.0:raiseValueError("Encountered value 1.0.") new_schedule.append(new_point) new_schedule.append(1.0)iflen(new_schedule) != n_chains:raiseException("This should not happen.")return jnp.asarray(new_schedule, dtype=float)
Let’s apply these utilities to suggest better annealing schedules for one of the problems above.
two samples: using initial (very quickly decaying schedule) and an optimised one,
two estimates of the \(\Lambda(\beta)\) function (each estimate depends on the schedule and the rejection rates collected during sampling),
three schedules: the initial one (decaying one), the optimised schedule (for which we also collected a sample), and a third, “very optimised”, schedule (which we estimated using the second one).
We hope that:
The second sample will be better than the first one (as the schedule now should be better).
The \(\Lambda(\beta)\) estimates will somewhat agree.
The second schedule will be much different than the second one. On the other hand, we can hope that the third schedule will be close to the second one (as it depends on the \(\Lambda\) function and we hope that the estimates are reasonable).
This looks pretty good to me! We see that the mixing has improved and the sample is of better quality. The \(\Lambda(\beta)\) differs a bit (resulting in a refined optimised schedule), but I would argue that this disagreement is reasonable. It also nice to see that the third schedule is close to the second one. In the paper, it is suggested to run the optimisation multiple times and the authors propose solutions how to allocate the computational budget within the preliminary runs and the last sampling phase.
Summary
I am very excited about parallel tempering! Some related thoughts:
Can we design other update schemes than DEO, which round-trip rate could be improved \(\Lambda\)? How to calculate the round-trip rate for a “full sweep” update scheme? Could alternating “full sweep forward” and “full sweep backward” improve the performance of the algorithm, or somewhat degenerate to the diffuse behaviour?
DEO removing dependency on \(N\) from SEO reminds me of preconditioned Crank-Nicolson algorithm, which works better than the random-walk Metropolis in high dimensions. Is it possible to somewhat formalise a possible connection between these ideas?
How to use parallel tempering when working with Gibbs samplers? Building a bridge through tempering between prior and posterior can break the conjugacy employed at some steps. Also, Gibbs samplers do not need to explore the prior (acting as the reference distribution) effectively enough.
How well can the data point tempering work, where the data set is artificially shrunk? This could be a potential bridge for Gibbs samplers (as we can simply consider different Gibbs samplers conditioned on subsets of the data sets as the local exploration kernels), but in the context of SMC samplers, there is a great 2007 paper from Ajay Jasra, David Stephens and Chris Holmes, showing that (at least for SMC samplers) the data point tempering seems to work worse than the likelihood tempering.
It is tempting to use priors \(p_0\) which are easy to sample from, but for which \(\log p_0(x)\) can be intractable. However, that one has to evaluate \(\log p_0(x)\) to construct the Markov kernels targeting intermediate distributions \(p_n\) for \(0 < n < N\). Only for swapping the chains we can rely just on the likelihood.↩︎